


Distributionally robust free energy principle for decision-making
分布鲁棒自由能原理及其在决策中的应用


摘要
尽管自主智能体取得了开创性的性能,但当训练和环境条件变得不一致时,它们可能会出现行为异常,即使是微小的不匹配也可能导致不理想的行为,甚至灾难性的失败。对于智能体而言,对这些训练 - 环境模糊性的鲁棒性是核心要求,而实现这一要求一直是它们在现实世界部署中长期面临的挑战。在此,我们介绍了一种分布鲁棒自由能模型(DR-FREE),该模型从设计上就赋予了这一核心属性。DR-FREE将自由能原理的鲁棒扩展与解析引擎相结合,将鲁棒性融入智能体的决策机制中。在基准实验中,DR-FREE使得智能体即使在最先进的模型失败的情况下也能完成任务。这一里程碑可能会激发在多智能体环境中的部署,并且或许在更深层次上,启发人们探索自然智能体——几乎没有或根本没有训练——是如何在反复无常的环境中生存下来的。
引言
设计自主智能体的一种流行方法是向它们提供数据,使用强化学习(RL)和模拟器来训练一个策略(见图1a)。基于这种范式设计的深度强化学习智能体已经展现出令人瞩目的能力,包括在《GT赛车》中超越人类冠军、玩《雅达利》游戏、控制等离子体以及在无人机竞赛中达到冠军水平的表现。然而,尽管它们取得了开创性的表现,但最先进的智能体在策略鲁棒性方面仍然无法与自然智能相媲美:自然智能体或许通过进化获得了决策能力,使它们能够在几乎没有或根本没有训练的情况下在具有挑战性的环境中发挥作用。相比之下,对于人工智能体而言,即使它们能够使用高保真度的模拟器,学习到的策略也可能对学习过程中可用的模型与真实环境之间的不匹配或模糊性表现出脆弱性(见图1b)。例如,无人机冠军和玩《雅达利》游戏的智能体都假设环境条件在训练过程中是一致的,如果这种假设失败,比如环境照明或物体颜色发生变化,或者无人机出现故障——使其动力学与训练期间可用的动力学不同——学习到的策略可能会失败。更一般地说,即使是微小的模型模糊性也可能导致在开放世界环境中出现非鲁棒行为和失败。实现对这些训练/环境模糊性的鲁棒性一直是设计能够在现实世界中运行的智能机器的长期挑战。
在这里,我们提出了DR-FREE,这是一个自由能计算模型,它解决了这一挑战:DR-FREE直接将这种智能的核心属性植入智能体的决策机制中。这是通过将DR-FREE建立在自由能最小化的基础上实现的,自由能最小化是信息论、机器学习、神经科学、计算和认知科学中一个统一的解释框架。该原理假设自然和人工智能体中的适应性行为源于变分自由能的最小化(见图1c)。DR-FREE由两个部分组成。第一部分是自由能原理的扩展:分布鲁棒(DR)自由能(FREE)原理,它从根本上重新定义了自由能最小化智能体如何处理模糊性。虽然经典的自由能模型(见图1c)通过基于智能体可用的环境模型来最小化自由能来获得一个策略,但在我们的鲁棒原理下,自由能则是在围绕训练模型的一个模糊性集合内的所有可能环境中被最小化。这个集合是根据训练模型周围的统计复杂性来定义的。这意味着智能体的动作是从一个策略中采样的,这个策略在模糊性集合中最小化了最大的自由能。鲁棒原理产生了策略计算的问题表述。这是一个具有自由能函数作为目标函数,以及用统计复杂性形式化的模糊性约束的分布鲁棒问题。这个问题不仅具有非线性成本函数和非线性约束,而且在决策变量上具有概率密度,为智能体提供了对不确定性和置信度的明确估计。这个框架的产物是一个最小化自由能且在模型模糊性上具有鲁棒性的策略。DR-FREE的第二个关键部分——它的求解引擎——是计算这个策略的方法。与基于自由能模型的传统策略计算方法不同,我们的方法表明,策略可以通过首先在模型模糊性集合中最大化自由能——在模糊性下提供一个成本——然后在策略空间中最小化自由能来方便地找到(见图1d)。简单来说,策略是在最坏情况下的最佳选择,其中最坏情况容纳了模糊性。当没有模糊性时,我们的鲁棒自由能原理产生了一个自然出现在学习——在最大扩散(MaxDiff)和最大熵(MaxEnt)的背景下——以及控制中的策略计算问题表述。这意味着DR-FREE可以产生不仅继承了这些方法的所有理想属性,而且确保它们在整个模糊性集合上的策略。在最大熵——和最大扩散——中,鲁棒性取决于最优策略的熵,在离散设置中可以得到策略鲁棒性的明确界限。为了计算一个鲁棒地最大化奖励的策略,最大熵需要与一个不同的、悲观的奖励一起使用——在DR-FREE中不需要这样做。我们自由能计算模型的这些理想特性是由它的求解引擎实现的。据我们所知,这是唯一可用的方法,用于解决由我们的鲁棒原理产生的完整的分布鲁棒、非线性和无限维策略计算问题;详细信息见结果部分和补充信息中的第S2节。在补充信息中,我们还强调了它与马尔可夫决策过程(MDPs)形式化方法的联系。DR-FREE产生了一个结构明确的策略:这是一个软最大值,其指数取决于模糊性。这种结构阐明了模糊性在最优决策中的关键作用,即它如何调节选择给定动作的概率。

DR-FREE不仅返回了我们自由能模型产生的策略,还确立了其性能极限。通过这样做,DR-FREE有两个含义。首先,DR-FREE策略是可解释的,并且支持(贝叶斯)信念更新。第二个含义是,面对模糊性的智能体不可能超过一个没有模糊性的智能体。当模糊性消失时,DR-FREE恢复了一个对其环境有完美知识的智能体的策略,没有智能体能够获得更好的性能。反过来,随着模糊性的增加,DR-FREE表明策略会降低智能体可用模型在模糊性上的权重。
我们在一个涉及真实探测器的实验测试平台上评估了DR-FREE,这些探测器的任务是在避开障碍物的同时到达期望的目的地。DR-FREE可用的训练模型是从有偏差的实验数据中学习的,这些数据没有充分捕捉到真实环境,并引入了模糊性。在实验中——即使存在由于从有偏差的数据中学习模型而产生的模糊性——DR-FREE成功地使探测器完成了它们的任务,即使在最先进的自由能最小化智能体和其他方法都难以完成任务的设置中。实验结果——通过在流行的高维模拟环境中评估DR-FREE得到证实——表明,为了在开放环境中运行,智能体需要内置的鲁棒性机制,这些机制对于补偿不良训练至关重要。DR-FREE提供了一个在问题表述中定义鲁棒性的机制,提供了这种能力。
我们的自由能计算模型DR-FREE揭示了自由能最小化智能体如何计算在问题表述中定义的模糊性集合上具有鲁棒性的最优动作。它建立了一个规范框架,不仅可以为基于自由能模型的人工智能体的设计提供鲁棒决策能力,还可以超越当前的自由能解释来理解自然行为。尽管取得了成功,但目前还没有理论解释这些自由能智能体是否以及如何在模糊性设置中计算动作。DR-FREE提供了这些解释。
结果
DR-FREE。DR-FREE 包括一个分布鲁棒的自由能原理以及相应的求解引擎——该原理(图 2a)是策略计算的问题陈述;求解引擎是策略计算的方法。该原理建立了一个序贯策略优化框架,其中随机化策略源于对模糊性下最大自由能的最小化。该求解引擎在策略空间中找到解决方案。这是通过计算——通过对模糊集中的所有可能环境的最大自由能——与模糊性相关的成本来实现的。然后,随后的最大自由能将在策略空间中被最小化(图 1d)。
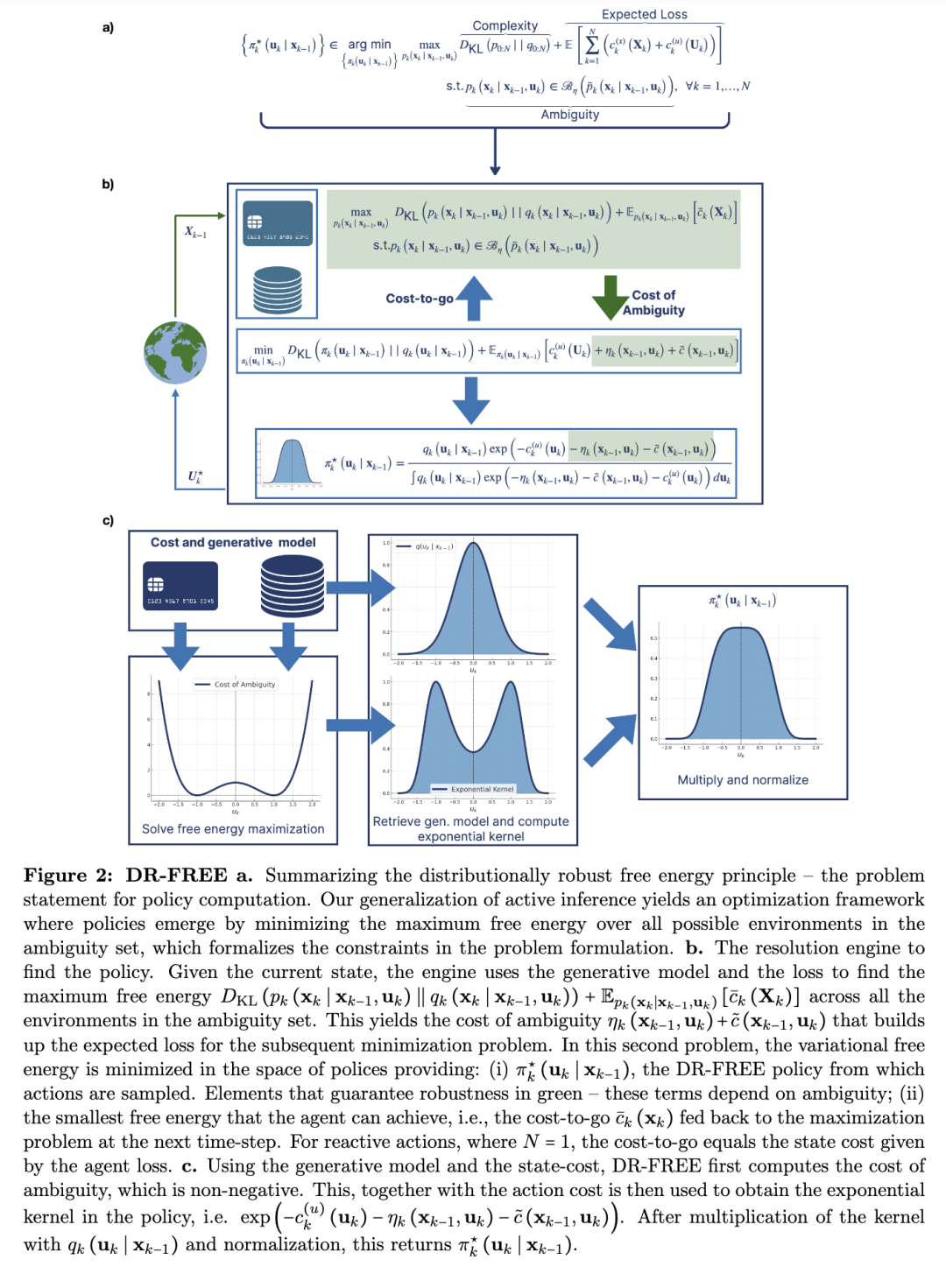



图 2a 中的策略优化问题是无限维的,因为最小化和最大化都在概率密度空间中进行。这使得对不确定性和模糊性的处理成为贝叶斯最优的,这将控制和规划表征为(主动)推断。DR-FREE 求解引擎——计算策略的方法——不仅找到策略,而且或许是反直觉地,返回一个具有明确且定义良好的函数形式的解。求解引擎背后的分析结果在 Supplementary Information 的 Sec. S3 和 Sec. S6 中。在总结中,这些分析结果表明,在每个 k k,最优策略可以通过双层优化方法找到,首先在模糊性约束下最大化自由能,然后在策略上最小化。虽然最大化问题仍是无限维的,但其最优值——产生模糊性成本——可以通过求解一个标量优化问题获得。这个标量优化问题是凸的并具有全局最小值。因此,一旦获得模糊性成本,随后的自由能可以在策略空间中被最小化,并且最优策略是唯一的。这些理论发现总结在图 2b 中。具体来说,时间步 k k的策略是一个 soft-max

DR-FREE 在模糊性无感知的自由能最小化代理失败时成功。为了评估 DR-FREE,我们特别考虑了一个实验,其中简单性是一个有意特征,以确保模型模糊性对决策的影响可以被识别、对文献中的方法进行基准测试46,并定量测量。该实验平台(图 3a)是 Robotarium47,提供硬件和高保真模拟器。任务是机器人导航:一个漫游者需要到达目标目的地,同时避开障碍物(图 3b)。在这一设置中,我们证明了一个模糊性无感知的自由能最小化代理——即使它做出最优动作——也不能可靠地完成任务,而 DR-FREE 成功了。文献中的模糊性无感知代理46通过求解图 2a 中问题的松弛版本(没有模糊性)来计算最优策略。这个代理求解了一个在学习和控制中相关的策略计算问题56——具有 DR-FREE 目标但没有约束。我们进行了多项实验:在每项实验中,DR-FREE 用于计算反应性动作,只访问训练模型



DR-FREE 阐明了模糊性在最优决策中的机制作用。DR-FREE 策略(图 2b)对与较高模糊性相关的状态和动作分配较低的概率。
用更简单的术语来说,一个遵循 DR-FREE 策略的代理更有可能选择与较低模糊性相关的动作和状态。DR-FREE 产生了代理行为在小模糊性和大模糊性两种体制下的特征描述。直观上,随着模糊性增加,DR-FREE 产生的策略将由代理的生成模型和模糊性半径主导。本质上,随着模糊性增加,DR-FREE 意味着代理将决策基于先验和模糊性,反映其对模型缺乏信心。相反,当代理对其训练模型有信心时,DR-FREE 返回一个自由能最小化代理的策略,在一个良好理解、无模糊性的环境中做出最优决策。





放松不确定性可以产生最大扩散。最大扩散(MaxDiff)是一种策略计算框架,它概括了最大熵(MaxEnt)并继承了其稳健性特性。它在流行的基准测试中表现优于其他最先进的方法。我们展示了当不确定性放松时,通过适当选择,分布稳健自由能原理(图2a)可以恢复MaxDiff目标。这明确地将DR-FREE与MaxDiff连接起来,并通过它与更广泛的稳健决策制定文献(补充信息的S2节)连接起来。在MaxEnt和MaxDiff中,稳健性保证来自于最优策略的熵,对于离散设置,可以在不确定性集上获得明确的后验界限,并具有恒定的不确定性半径。为了计算稳健最大化奖励的策略,必须使用辅助的、悲观的奖励来使用MaxEnt。相比之下,通过解决图2a中的问题,DR-FREE直接在问题表述中定义了稳健性保证,明确地通过不确定性集。因此,DR-FREE策略保证在这一不确定性集上是稳健的。如补充信息的S2节所详述,据我们所知,图2a中的完整最小-最大问题——同时具有自由能目标和分布稳健约束——对许多方法来说仍然是一个挑战。这不仅仅是一个理论上的成就,它独特地将DR-FREE定位在文献中——我们通过重新审视我们的机器人导航任务来探索其影响:我们为DR-FREE配备了一个生成模型,该模型恢复了MaxDiff目标,并比较了它们的性能。实验表明,DR-FREE在MaxDiff失败的环境中取得了成功。这是因为DR-FREE不仅保留了MaxDiff的理想特性,而且还在不确定性集的最坏情况下保证了它们。






最后,我们在 MuJoCo 的蚂蚁环境中评估 DR-FREE(图 5a)。目标是让四足代理在保持直立姿势的同时沿 x 轴向前移动。每个回合持续 1000 步,除非蚂蚁变得不健康——这是标准环境中定义的失败条件。我们将 DR-FREE 与所有先前考虑的方法以及模型预测路径积分控制(NN-MPPI)进行比较。在所有实验中,代理都可以访问训练好的模型。训练好的模型是使用与原始 MaxDiff 论文中相同的神经网络架构获得的,该论文还包括了与 NN-MPPI 的基准测试。提供给代理的成本在所有实验中都是相同的,对应于标准环境中定义的负奖励。图 5b 显示了该设置的实验结果。实验得出两个主要观察结果。首先,DR-FREE 的表现优于所有比较方法,平均而言,即使其他方法的最高误差条(其他方法的平均值的标准差)也不及 DR-FREE 的平均回报。其次,在一些试验中,其他方法会因为蚂蚁变得不健康而提前终止回合。相比之下,在所有 DR-FREE 实验中,蚂蚁始终保持健康,因此回合不会提前终止。有关详细信息,请参阅方法和补充信息中的实验设置;代码也已提供。

鲁棒性是智能代理在现实世界中操作的核心要求。与其将这一要求的实现留给——引用文献5——训练中出现的潜在脆弱属性,DR-FREE通过设计确保了这一核心要求,基于自由能的最小化,并将顺序策略优化安装到一个严格的(变分或贝叶斯)框架中。 DR-FREE不仅提供了一个考虑环境不确定性的自由能原理,还提供了解决由此产生的顺序策略优化框架的解析引擎。这一里程碑很重要,因为它解决了智能机器在开放世界中操作的挑战。在此过程中,DR-FREE阐明了不确定性对最优决策的机制作用及其策略支持(贝叶斯)信念更新。DR-FREE确立了在不确定性面前的性能极限,显示出在非常基础的层面上,受不确定性影响的代理不可能超越无不确定性的自由能最小化代理。这些分析结果通过我们的实验得到了证实。
在导航实验中,我们将一个对不确定性不敏感的自由能最小化代理的行为与装备有DR-FREE的代理的行为进行了比较。所有实验都表明,DR-FREE对于机器人在不确定性中成功完成任务至关重要,当我们考虑额外的基准测试和不同环境时,这一点得到了证实。DR-FREE能够重建支持其在相关方法中表现优越的成本函数。我们的实验设置不仅对智能机器来说是典范的,强调了不确定性的严重后果,而且对自然智能也是如此。例如,通过进化适应,细菌可以导航未知环境,这种对生存至关重要的能力是在几乎没有或没有训练的情况下实现的。DR-FREE表明,如果细菌遵循一种决策策略,虽然简单,但预见了促进鲁棒性的步骤,这可能是可能的。跑-停运动可能是一种精明的方式实现这一点:通过DR-FREE解释,翻滚可能是由自由能最大化驱动的,需要在环境中量化不确定性的成本,而跑步则是从考虑这一成本的自由能最小化策略中采样的。 DR-FREE提供了一个通过自由能最小化实现鲁棒决策的模型,鲁棒性保证在问题表述中定义——它还开启了许多跨学科研究问题。 首先,我们的结果表明,从这项工作中产生的一个有前途的研究方向是将DR-FREE与感知和学习相结合,将训练与策略计算耦合。该框架将在策略计算问题的表述中嵌入分布约束,如在DR-FREE中一样,同时保留受例如MaxDiff和/或证据自由能最小化启发的感知和学习机制。该框架将激励分析研究,以量化集成学习相对于离线管道的好处。沿着这些思路,应该开发分析研究来扩展我们的框架,使其能够明确考虑代理成本/奖励中的不确定性。其次,DR-FREE将不确定性半径作为输入,这激发了在我们模型中推导半径估计机制的动机。通过我们的分析结果,我们知道减少不确定性可以提高性能;因此,在我们的框架中整合一种学习不确定性的方法将是朝着不仅鲁棒而且反脆弱的代理迈出的有前途的一步。最后,我们的实验引发了一个更广泛的问题:在不确定性存在的情况下,什么构成了一个好的生成模型/规划视野?答案仍然难以捉摸——DR-FREE保证了对不确定性的鲁棒性,实验表明它可以补偿糟糕的规划/模型;然而,例如,通过更多的任务导向模型/规划,对不确定性不敏感的代理可能会成功。这产生了一个后续问题。在具有挑战性的环境中,专用模型是否比多用途模型更有利于生存?
如果,引用流行的格言,所有模型都是错误的,但有些是有用的,那么放宽对训练的要求,DR-FREE使更多模型变得有用。这是通过偏离强调训练的作用和重要性的观点实现的:在DR-FREE中,重点反而在于严格地将鲁棒性安装到决策机制中。凭借其鲁棒的自由能最小化原理和解析引擎,DR-FREE表明,沿着这条道路,智能机器可以从很大程度上不完美,甚至糟糕的模型中恢复鲁棒策略。我们希望这项工作能够激励我们在多智能体设置中部署我们的自由能模型(具有异构代理,如无人机、自主船只和人类)跨越广泛的应用领域,并结合DR-FREE与深度强化学习,导致学习方案——学习不确定性——在经典方法失败时成功。在可能更深层次的层面上——因为不确定性是心理学、经济学和神经科学等跨学科领域的关键主题——我们希望这项工作能够为自然代理如何在几乎没有或没有训练的情况下在具有挑战性的环境中稳健操作提供生物学上可信的神经解释的基础。
方法


这是对自由能原理的一个扩展,考虑了策略对模型不确定性的鲁棒性。我们没有意识到其他任何考虑这种设置的自由能账户,以及相应的无限维优化框架无法用优秀的方法解决。当移除不确定性约束且损失为负对数似然时,我们的公式简化为主动推理中的预期自由能最小化。在这个特殊情况下,预期的复杂性(即不确定性成本)变成了风险;也就是说,推断结果与首选结果(即训练结果)之间的KL散度。预期自由能可以表示为风险加上不确定性;然而,预期自由能中的不确定性涉及生成模型中似然映射的不确定性(即条件熵),而不是我们自由能模型中考虑的关于生成模型的不确定性。 在鲁棒和传统的主动推理中,复杂性项在最优控制和杰恩斯的最大口径(也称为路径熵)或最小熵产生原理之间建立了密切的关系。值得注意的是,为我们在主动推理中的自由能最小化提供一般化,我们的鲁棒公式产生了其他流行的计算模型,如KL控制、控制作为推理和线性二次高斯调节器。此外,当损失为负对数似然时,成本函数中变分自由能的负值是证据下界,这是机器学习和逆强化学习中的一个关键概念。凭借其解析引擎,DR-FREE表明在这个非常广泛的设置中,仍然可以计算出最优策略。将MaxDiff与DR-FREE联系起来。我们首先展示图2a中的鲁棒自由能原理公式具有与(1)相同的最优解。我们有以下恒等式:

解析引擎。变分自由能和不确定性约束在无限维决策变量中都是非线性的,这带来了许多挑战,我们通过解析引擎来解决这些问题。解析引擎允许我们处理由我们的鲁棒自由能原理产生的顺序策略优化框架。我们在这里详细说明解析引擎,并参考补充信息以获取正式处理。我们的起点是通过上述顺序策略优化框架制定的鲁棒自由能原理。这可以通过向后递归来解决,其中开始,在每个 k 时需要解决以下优化问题:





主论文中的成本重建是通过找到对问题最优的权重来获得的,即在去掉成本中的第一项后,因为它不依赖于权重。问题的凸性随之而来,因为成本函数是凸函数的锥形组合。详见补充信息。




原文:https://arxiv.org/pdf/2503.13223




















热门跟贴