


现在的AI老师,它能听懂你含糊不清的方言提问。

关键是,它还能同时教一百万人,还个个都“量身定制”。
这事儿听着玄乎?
但就在2026年初,一家叫「与爱为舞」的公司,真把这事干成了。

咱们以前用的大模型,说白了就是个“知识库+嘴替”。
题目一丢,答案秒出,逻辑看似严谨,实则毫无教学温度。

孩子问了个语法题,AI直接甩出“expect to do sth.”的规则,还附赠一份动词清单。
这不是教学,这是知识倾销。
但「与爱为舞」不一样。他们没止步于“答对题”,而是花了大功夫让AI学会“怎么教”。
怎么做?核心就俩字:知行合一。

“知”的层面,他们构建了覆盖全学科的知识图谱和考点体系,更关键的是,把上百位顶级名师的授课视频拆解成“思维链”,总结出“好老师红宝书”。
比如一个知识点该怎么引入、学生卡在哪要停顿、用什么例子能激发兴趣。这些不是冷冰冰的规则,而是活的教学智慧。

“行”的层面更硬核。
他们用百万小时真实课堂数据训练AI,还搞出“虚拟学员”跟AI对练,每周生成数万小时合成数据。
AI不是在背教案,而是在“实战”中学会因材施教。
更绝的是,他们用强化学习(GRPO)给AI设了“教学KPI”:不光要看讲得对不对,还要看节奏好不好、互动灵不灵活。

最终,AI得通过“模拟课堂”和“真实学员试讲”两轮考核,才算拿到“教师资格证”。

光有脑子不够,AI导师还得有“感官”。最大的痛点是什么?听不清!
普通语音识别在安静环境下准确率也就80%左右,一旦家里开着电视、孩子带点口音,基本就废了。

「与爱为舞」自研了多模态语音理解大模型,不仅能“听声”,还能“读境”——结合当前讲到的知识点、对话历史,智能判断你说的是哪个词。
再加上声纹降噪技术,能区分孩子和家长的声音。结果?句准确率从80%飙到95%以上,接近真人水平。

说完“耳朵”,再看“嘴巴”。市面上多数AI语音合成,一听就是机器人——平、假、机械。
甚至为每位合作名师单独录制声线样本,还原真实“人味”。
更关键的是“实时交互”。孩子打断提问,AI能不能立刻响应?

他们研发了流式语义VAD和打断模型,识别打断意图准确率超90%,响应延迟压到200毫秒内。
配上同步口型、表情、手势的数字人,整个教学过程流畅自然,孩子不容易走神。

最让人惊讶的,是它竟能支撑百万级用户并发。
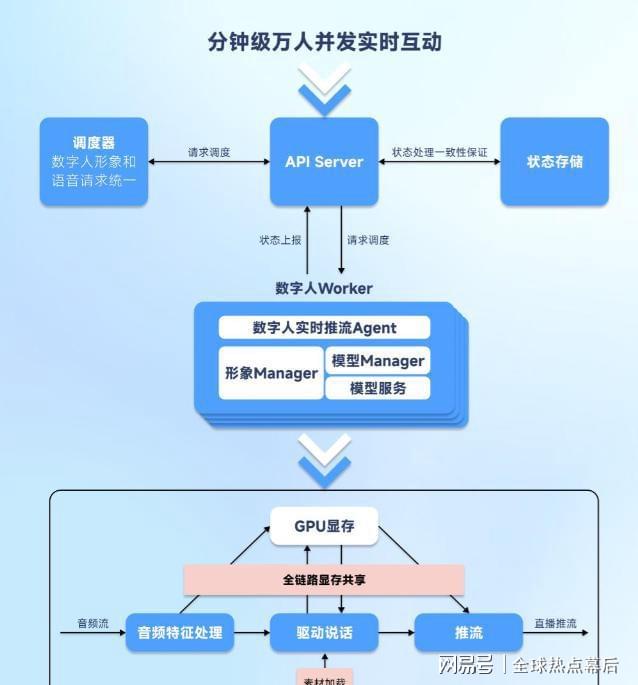
要知道,从语音识别→大模型推理→语音合成→驱动数字人,整条链路极其耗资源。稍有延迟,体验就崩。
「与爱为舞」的解法很聪明:借鉴《思考,快与慢》里的“双系统”理论。
简单问题走“快通道”,复杂问题才调用大模型。同时后台预加载、结构化Prompt、高频答案缓存……

一套组合拳下来,端到端响应稳定在1–1.6秒。
底层工程更是狠活:单卡显存统一规划、算子专项加速,一张GPU能扛几十路数字人;集群层面实现多形象统一调度、任务组件化、并行计算、弹性扩容。
这才让“千人千面”真正规模化落地。
据最新消息,其产品“爱学”已服务超百万用户,覆盖全国342个城市,东至佳木斯,西达克孜勒苏,南抵三沙,北至大兴安岭。
偏远地区的孩子,也能拥有“真人级”AI名师。

两千多年前,孔子提出“有教无类、因材施教”,却受限于时代,只能成为理想。
今天,AI终于让这一愿景照进现实。它不是取代老师,而是把顶级教学能力普惠化。
当技术真正服务于人的成长,教育的公平与质量,才有可能同时实现。
这,或许才是AI最值得期待的模样。






















热门跟贴