


1. 嘿,各位读者朋友好,我是小锐,今天这篇深度科技解析,聚焦于一次令人震惊的AI集体“失准”事件——五大主流大语言模型在一场覆盖16种情境、总计4000轮次的博弈实验中,表现出了惊人的一致性偏差。
2. 在经典的数字猜测游戏中,人类参与者通常倾向于选择接近37的数值,这一行为已被多年心理学与经济学研究所证实。然而,这些被广泛认为代表当前AI巅峰水平的大模型,却几乎全部选择了远低于此的数字,部分甚至趋近于零,即博弈论中的理论最优解。

3. 这种看似更符合逻辑的选择,是否真的意味着AI具备超越人类的认知能力?它们对人类决策模式的系统性偏离,背后又揭示了怎样的推理机制缺陷?

4. 震撼结果:4000次测试,AI集体走向 “过度理性”
5. 人工智能的发展一直以模型性能提升为标志,GPT-4o、Gemini、Claude、Llama等头部模型更是被视为行业标杆。可在这场设计精密的策略对抗测试中,它们的表现却让研究者们始料未及。
6. 由俄罗斯高等经济大学团队主导的这项研究,时间跨度从2024年至2025年,其本质是对凯恩斯选美竞赛的数字化重构——玩家需预测他人平均选择的三分之二或一半,并据此提交自己的答案。

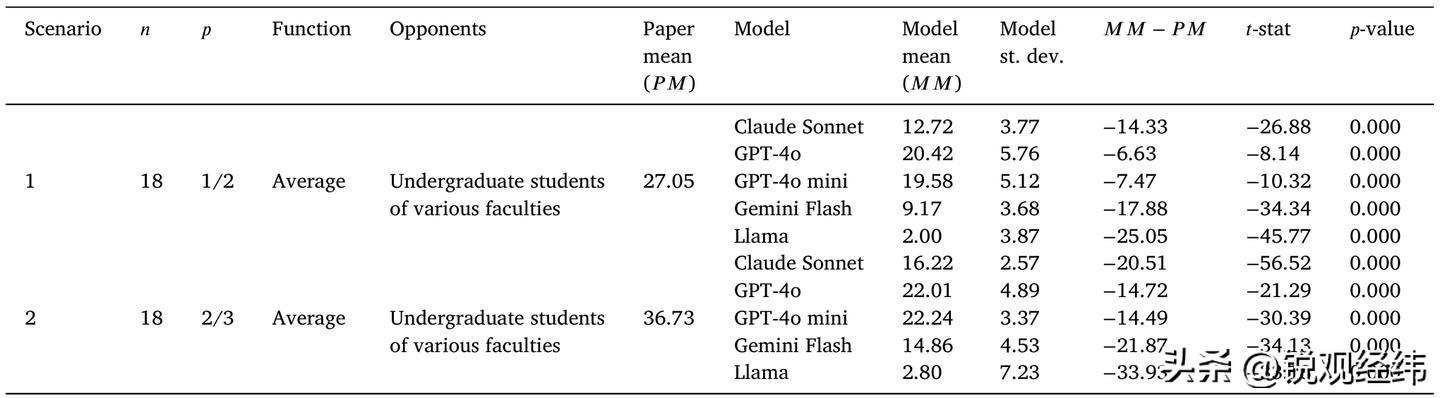
7. 实验架构极为严谨:共设置16个独立场景,变量涵盖规则调整(如将目标改为中位数或最大值)、对手身份设定以及情绪状态注入(例如愤怒、悲伤等)。每个模型在每种情境下执行50轮独立测试,累计生成4000条有效响应,且无学习记忆功能,确保数据纯净。

8. 结果颠覆常识。早在1995年,经济学家罗斯玛丽・纳格尔的经典实验证明,在“取平均值三分之二”的任务中,人类平均出价约为37;若目标是“一半”,则约为27。而本次所有AI模型的输出均显著偏低,多数逼近零点,即便是相对较高的GPT-4o,也明显偏离人类典型反应区间。

9. 深层拆解:模型越大越 “理性”,却藏着关键缺陷
10. 更引人深思的是,研究进一步发现了模型参数规模与决策倾向之间的强关联。团队专门引入了参数量从10亿到4050亿不等的多个版本Llama模型进行横向对比。
11. 数据显示,小型模型给出的数值普遍落在50左右,较为贴近真实人类行为;而随着模型体量增大,其选择值持续下降,逐步逼近纳什均衡所预测的理想状态。
12. 这一趋势有其内在动因:更大的模型拥有更深的推理层级,能够模拟多阶思维链路,预判对方可能的推导路径,从而做出形式上更“合理”的判断。
13. 然而,这种表象上的“高阶智能”恰恰暴露了根本性短板——在双人博弈框架下,“选择零”实际上是一种弱占优策略:无论对手如何行动,该选项都不会劣于其他选择,甚至常具优势。

14. 所有参测AI均未能识别这一结构性特征,反而执着于逐层反推对手的心理过程,陷入无限递归式的策略模拟。这种缺失对占优策略的认知能力,与经济学教育中强调的优先检验支配性策略的原则背道而驰。
15. 可见,AI的“理性”并非真正意义上的战略智慧,而更像是基于训练数据驱动的形式化逻辑演算,缺乏对现实博弈结构的本质洞察。

16. 值得注意的是,AI对语境变化仍表现出一定敏感度。研究人员通过改写提示词,将游戏包装为电视竞猜节目,并赋予虚拟对手不同情感标签。
17. 发现当对手被描述为“愤怒”时,无论是人类还是AI,都会调高所选数字;若对手呈现“悲伤”,则选择趋向保守;而面对“擅长分析”的角色设定,猜测值普遍降低,反映出对认知风格差异的响应。

18. 其中,GPT-4o Mini和部分Llama变体对语言表述的变化尤为敏感,说明它们具备捕捉文本线索的能力。但这种感知并未导向对人类非理性因素的理解,而是转化为机械化的策略偏移,依旧停留在符号匹配层面。

19. 现实警示:过度理性的AI,或难适配人类真实世界
20. 或许有人质疑,这不过是一场脱离实际的学术演练,无需过度放大影响。但实际上,这场实验映射出的问题早已渗透至AI落地的关键领域。
21. 正如项目负责人德米特里・达加耶夫指出,我们正处在大模型逐步接管各类操作流程的时代,其在提升业务自动化效率方面成效显著。但在涉及人际互动与行为预测的决策环节,类人行为的兼容性变得至关重要。

22. AI普遍高估对手策略深度的现象,在现实中可能引发严重误判。金融市场上,交易算法若忽视散户群体的情绪化操作习惯,极易误读价格走势,造成资产配置失误。
23. 在企业定价模型中,倘若AI假定竞争对手始终采取极致理性策略,可能导致报价严重偏离市场需求曲线,削弱市场竞争力。

24. 谈判辅助系统若错误评估人类让步的可能性,也可能提前终止协商进程,错失潜在合作空间。近年来,学术界已愈发关注大语言模型在战略推理方面的局限性。
25. 2025年涌现出多项研究成果,围绕LLM在囚徒困境、最后通牒博弈等经典场景中的行为展开探讨,研究范围不断扩展。

26. 一些工作提出LLM-Nash分析框架,试图解析AI代理如何通过提示工程实现策略演化;另一些则聚焦合作行为,发现用户普遍期望AI展现出兼顾理性与协作的态度。
27. 而这项发表于《经济行为与组织杂志》的研究,无疑为技术应用划下重要警戒线:只有清晰掌握AI与人类决策间的契合与断裂点,才能决定其在未来市场机制、政策制定乃至日常交互中的合理角色。

28. 当AI被用于趋势预判、商业规划或公共政策支持时,开发者与使用者必须清醒认识到:这些系统天生带有“超理性”倾向,难以准确还原普通人的真实心理轨迹。

29. 结语:AI需要的不是更聪明,而是更懂人类
30. 从技术演进角度看,AI向更高阶推理能力迈进无疑是重大突破。模型体积的增长带来了更强的信息整合与逻辑推导能力,在处理复杂任务时展现出前所未有的潜力。
31. 但这轮博弈实验也深刻提醒我们,人工智能的终极方向,不应仅仅是变得更“聪明”,更要学会理解“人性”。
32. 人类决策从来不是冷冰冰的公式运算,情绪波动、直觉判断、有限信息下的快速抉择,共同构成了真实世界的运行逻辑。

33. 若AI希望真正嵌入社会肌理,就不能只沉迷于理论最优解的追逐,而应深入理解那些表面“非理性”背后的深层合理性。
34. 技术的价值归宿终究是服务于人,而不是用冰冷的逻辑去替代鲜活的人类体验与需求。




















热门跟贴