


来源:市场资讯
(来源:51CTO技术栈)

今天,月之暗面开源模型 Kimi K2.6 重磅发布!
这一模型是其迄今为止最强的代码模型,不仅在全球开源SOTA中领先,而且击败了GPT-5.4和Claude Opus 4.6。
一个开源模型,对闭源模型几乎形成了压制性优势。
同时,Kimi K2.6 可以连续编码 12 小时,只需一个提示词就能调用300 个子 Agent 并行完成 4000 个协作步骤。
为 Kimi 团队喝彩打call!Bravo!!!

有位网友评价:“新的Kimi模型简直是头猛兽。”

还有人说“AI军备竞赛不是美中之争。这是封闭式和开放式的区别。而Closed一直在输。”

这次浓墨重彩的更新中不仅有精彩的跑分,其长时程编码和Agent集群功能也非常值得好好说道说道。话不多说,首先让我们来看基准跑分。
基准测试
在编程和Agent方面的基准测试情况是:


在这些编码和Agent的基准测试中 K2.6 几乎全部领先,另外推理和视觉也都没落下:
Toolathlon: 50.0
MathVision w/ Python: 93.2
Charxiv w/ python:86.7
在X上,还有人将K2.6 与 K2.5、Mythos、Opus 4.7 以及基于 K2.5 的 Cursor Composer 2 进行了全方位比较,最后得出结论:这是一个非常好非常好的模型。


长时程编程:连续编码12小时
K2.6这次耐力拉满,在长程代码任务上完成了教科书级的突破。
面对不同编程语言(如 Rust、Go、Python)和任务场景(如前端、运维、性能优化),K2.6 都轻松拿捏,相较于 K2.5 能力显著提升,具备更可靠的泛化能力。
在官方让K2.6完成的真实场景挑战中,K2.6做到的“连续编码12小时”让社区中的众多网友啧啧称赞。
这次挑战的全程经过是K2.6 在 Mac 本地做到了一个“不可能完成的任务”:下载并部署 Qwen3.5-0.8B 模型。最绝的是,它选择用极其冷门的 Zig 语言重新实现并优化推理过程。
在这次任务中它不仅连续作战 12 小时,不眠不休;还经历了 14 轮迭代、超过 4000 次工具调用。
最终, 它战果是将吞吐量从初始的 15 tokens/s 狂飙到了 193 tokens/s!最终甚至比知名工具 LM Studio 还要快 20%。这泛化能力,只能说:还有谁?

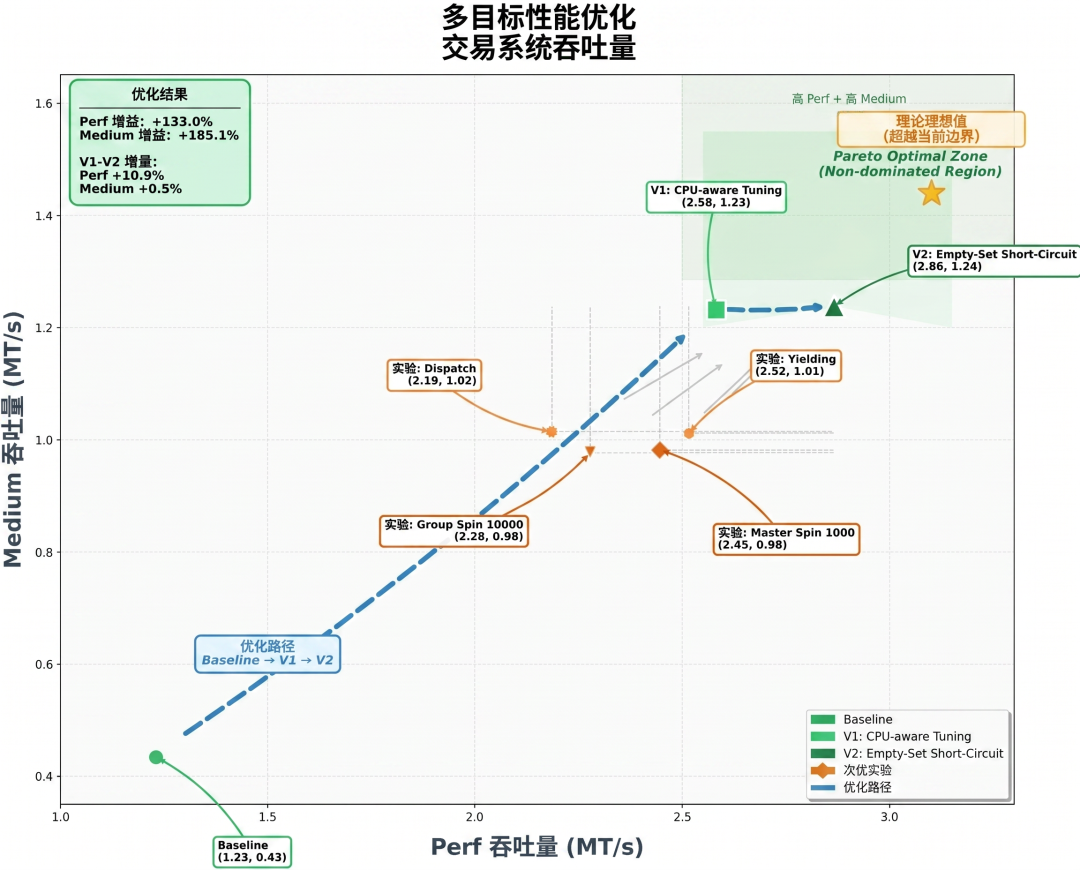
另一个挑战更加硬核,面对拥有 8 年历史的开源金融引擎 exchange-core,K2.6 像顶级架构师一样,对其进行了深度调优和硬核重构。
它盯着 CPU 和内存分配火焰图找 Bug,历经 13 小时的连续作业,修改了 4,000 多行核心代码,甚至大胆改变了线程拓扑结构。
最终在系统性能几乎触顶的情况下,硬生生把中位吞吐量提升了 185%(0.43 飙到 1.24 MT/s),峰值吞吐量更是暴涨 133%!
现在的Kimi K2.6可以说是能带飞的超级编程队友,不仅能深挖性能瓶颈、精通全栈语言,还能打“长久战”。
前端设计优于 Gemini 3
除此之外,K2.6 还能用编码驱动设计,无论是极具设计感和视觉冲击的网页首屏,还是动感十足的滚动触发效果,它都能信手拈来。

凭借进阶的多模态编程能力,它能精准地“看懂”图像和视频素材,并瞬间把它们转化成像素级的网页代码。你的灵感,它能秒变现实。
此外,月之暗面还专门创建了前端开发设计评测标准Kimi Design Bench,包括视觉输入任务、落地页构建、全栈应用开发以及通用 Web 开发这四个维度。
对比 Google AI Studio 里的 Gemini 3 模型,在这套评测中 K2.6 展示出了极其明显的断层式领先优势!

能力扩张的Agent集群
相较于K2.5能调动的100个子Agent和同时执行1500个步骤,K2.6的能力规模已扩大至最多能指挥300个子Agent和执行多达4000个协作步骤。
在K2.6 的世界里,Agent 集群不仅能动态拆解复杂任务,还能自主调度不同技能特长的 Agent 互补协作。
搜索、深研、分析、创作,每个 Agent 都有自己的“绝活”。跑一次任务,它能顺手把文档、网页、PPT 和表格全给你做出来。简直像是完整的智力团队钻到了你的电脑里。
在实测展示中,面对全球 100 个半导体标的,Agent 集群一口气设计并执行了 5 套量化策略,把麦肯锡风格的 PPT 逻辑直接“吸取”为可复用技能,最终交出了一套专业建模表格和全套汇报 PPT。估计投行分析师看了可能都想直呼“内行”。

更适配OpenClaw/Hermes
在Agent方面,除了规模化的Agent集群,K2.6的开发还考虑了与OpenClaw/Hermes地框架如何更好地协同。
K2.6 在需要跨应用、全天候待命的OpenClaw/Hermes式任务中,自主执行能力显著增强。
在Kimi的官方博客中,他们提到团队的RL基础设施团队搞了个硬核测试:让基于 K2.6 的 Agent 连续自主运行了 5 天!

从日志中可以看到,K2.6 的API调用不仅更加精准,而且更加稳定,同时“安全意识”也变更强了。

此外,在在 Kimi 内部的“魔鬼基准测试” Claw Bench 中,K2.6 比 K2.5 的综合性能提升了10%。
K2.6当Agent群群主
有意思的是,Kimi团队还探索一个Agent领域的新方向:Claw群组。
这是他们正在小范围内测的神秘功能。

Claw群组主打“海纳百川,有容乃大”,无论Agent 是跑在本地笔记本、手机还是云端服务器上,还是来自不同供应商、使用的是不同模型,都可进群。
而且,每个进群的Agent 都可以携带自己的专属工具包、独特技能和“持久化记忆”。
在这个群里,K2.6 担任的是核心协调者的角色。它能把不同任务配置给最适合的Agent,还可以在Agent突然“掉线”或者任务卡壳时,重新分配任务或生成子任务来救场。
从任务启动到验证再到最后交付,K2.6 全程盯盘,如同一个稳健的项目管理经理。
这次K2.6的发布可以说真正打破了“闭源垄断”,开启了开源前沿时代。
过去,前沿能力几乎被OpenAI、Anthropic等少数闭源巨头把控,研究者和开发者只能通过昂贵API“租用”。Kimi K2.6是首个同时在多个核心Agent/编码基准上超越闭源SOTA的开放权重模型,这标志着“开源已能匹敌甚至领先闭源”。
它直接把最先进的Agentic AI(能自主长期规划、调用工具、协同工作的AI)推向了社区,任何有GPU的人都能下载、微调、部署。这极大降低创业和创新成本、也会极大加速全行业创新速度,促进了全球科技平等。




















热门跟贴