


01 沐曦股份产业链全景

02 公司历史时刻

03 主要业绩数据
公司 2022 到 2024 年的营收,从小买卖一路冲到大盘子:2022 年只有 42.64 万(差不多小门店的流水),2023 年跳到 0.53 亿,是去年的 124 倍;2024 年直接干到 7.43 亿,是 2023 年的 14 倍。但这三年一直在砸钱铺业务,净利润年年亏:2022 亏 7.77 亿,2023 亏 8.71 亿(比去年多亏 12%),2024 亏 14.09 亿(比去年多亏 61%)。
2025 年前九个月,营收直接冲到 12.36 亿,是去年同期的 5.5 倍;净亏 3.46 亿,比去年同期少亏了一半多。

04 上游产业链--核心供应
沐曦的上游供应商主要是晶圆制造、芯片封装测试、存储颗粒、IP 及 EDA 工具、其他电子元器件厂商,就像手机厂商依赖芯片、屏幕供应商,这些上游配套的产品质量、生产良率、供货稳定性以及价格波动,都会和芯片设计行业紧密绑定、相互影响。发行人具体采购情况如下:

沐曦是 Fabless 模式的芯片设计公司,就像只做服装设计不自己开工厂的团队,核心聚焦研发和销售,无需消耗生产环节的大量能源,日常经营仅需少量办公水电,由办公场所配套供应,报告期内该类能源供应始终稳定。
下方扫码直接加入:
05 中游产业链--核心产品
沐曦股份是国内高性能通用 GPU 领域的领军企业,2020 年在上海成立,核心业务是研发、设计并销售覆盖 AI 训练推理、通用计算、图形渲染的全栈 GPU 产品,还配套提供软件栈与计算平台。
就像打造 “算力全家桶”,公司从指令集、微架构等 GPU IP,到 GPU SoC、高速互连技术再到配套软件,积累了全链条核心技术,成为自主研发高性能 GPU 芯片及计算平台的核心玩家。同时,沐曦股份构建了 “1+6+X” 的生态与商业布局:

沐曦的产品端全面覆盖三大核心领域,推出曦思 N 系列(智算推理)、曦云 C 系列(训推一体 + 通用计算),图形渲染专用的曦彩 G 系列也在研发中。

05-1、芯片设计生产
沐曦的芯片设计是核心技术所在,其自身主导了绝大部分的流程:

05-2、核心产品介绍
目前,公司现在卖的产品形态挺齐全:既有带 GPU 芯片的核心配件(像电脑里的独立显卡板卡 / 模组),也有现成能用的整机(服务器、一体机、工作站),还有把多台服务器、存储设备、网络设备连起来的 “超级计算组合”(智算集群)。
未来,其重点发力的是 GPU 板卡这款核心配件。销售上走 “两条腿走路” 的路子,既自己直接对接客户,也靠经销商帮忙铺货,同时一直跟着服务器 OEM 厂商、经销商深化合作,把合作网铺得更宽更牢。

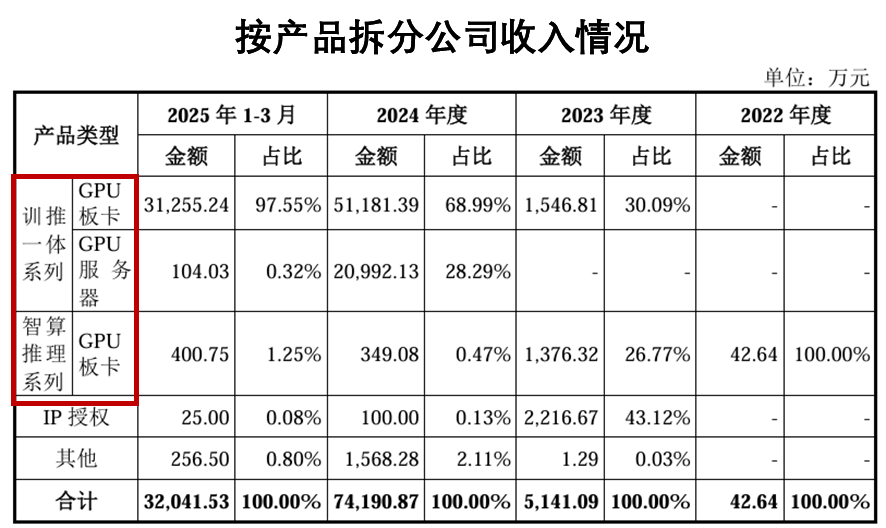
2024 年和 2025 年一季度,公司带来收入的 GPU 产品主要分两大块 —— 训推一体系列和智算推理系列。训推一体卖的是 GPU 板卡和服务器,具体型号是曦云 C500、C550;智算推理对应的是 GPU 板卡,型号是曦思 N100、N260。
公司的 GPU 产品矩阵分三类:曦思 N 系列专做智算推理,曦云 C 系列负责训推一体和通用计算,曦彩 G 系列主打图形渲染—— 把训练、推理、通用计算、渲染这些场景全覆盖了。

收入的核心来源是训推一体的曦云 C500 系列:2023 年它贡献了 1547 万元,占主营业务收入的 30%;2024 年直接冲到 7.2 亿元,占比涨到 97%;2025 年一季度收了 3.1 亿元,占比进一步提到 98%,成了收入的绝对顶梁柱。

05-3、核心竞争力
对比国内外的同行业企业,沐曦股份的核心竞争力体现如下:

(1)单卡性能、生态兼容性领先
沐曦自己做了从底层到成品的高性能 GPU 芯片和计算系统,攒下了不少核心技术 ——GPU 的 “地基”(像 IP、指令集、架构这些底层核心技术)全是自己掌控的。
曦云 C 系列 GPU 芯片,是国内少有的能做到高数据传输速度、还能把几十张卡连起来用的产品:
①所有产品用一套 XCORE 底层架构,既能通用于不同场景又性能强,像手机统一系统版本一样,方便快速升级迭代;
②靠自家 MetaXLink 技术,单颗芯片带 7 个高速连接口,能把 2 张、4 张一直到 64 张卡拼成不同的组合用;
③硬件层面,C500 的算力在国内排第一档;存储用了高速的 HBM2e,更快的 HBM3 也在研发中;连卡能力能从 2 张扩到 64 张。软件上自己做的 MXMACA 框架,能兼容行业常用的 CUDA,既好用又能适配多数场景;
④招股书显示,曦云 C500 的综合性能能对标英伟达 A100,而且在大模型训练场景里,比现在国内能买到的英伟达 H20 表现更好。

(2)集群性能:千卡集群落地,国内少数能做到的玩家
沐曦股份是国内少数能把 “千卡级 GPU 集群” 做成成熟生意的公司,还在推进 “万卡级集群” 的落地。
2025 年一季度靠相关项目实现 2.49 亿元收入,其中已投入使用的产品贡献 1.22 亿元,这两项收入分别占主营业务收入的 77.83% 和 38.23%,而已投用产品收入占比不高,核心是 4096 卡规模的项目 C(一期)尚未完工,该项目预计 2025 年 9 月正式投用。

(3)软件生态:自研MXMACA栈+CUDA高度兼容,适配无门槛
沐曦自主打造的 MXMACA 软件栈,就像一套配齐开发、调试、性能优化全流程工具的 “万能工具箱”,还能无缝对接行业主流的 CUDA 生态、支持 6000 多款相关应用。
截至 2025 年 7 月 31 日注册用户超 1.5 万人,其从上层到下层分为四层:算法应用层(含各类 AI 框架、模型和应用)、数学库及通信库层(含自研和适配的第三方软件库)、编程语言层(含高低级语言支持及编译器、转换工具)、软件驱动层(含驱动程序和性能分析、调试等工具)。

(4)创新多种超节点形态
沐曦股份推出多款超节点 “算力积木”,包括 16-64 卡光互连超节点、32/64 卡耀龙 3D Mesh 超节点及 128 卡 Shanghai Cube 国产高密度液冷整机柜。
2025 年 3 月发布的第一代 Shanghai Cube 超节点服务器专为大规模 AI 训练与推理设计,搭载曦云 C550 系列芯片定制化 OAM 模组,以 47U 单机柜 4 组超节点(每组 32 卡)的 128 卡液冷高密度部署,8 机柜即可组成千卡集群。

06 下游产业链——应用场景

07 创始人及团队介绍

陈维良,沐曦集成电路创始人、董事长兼 CEO,电子科技大学本科、清华硕士毕业。深耕芯片领域 20 余年,AMD 任职 17 年,主导 15 款高性能 GPU 量产,是 RDNA/CDNA 架构核心研发者。
2020 年联合骨干创立沐曦,攻坚全栈国产 GPU,5 年推动公司科创板上市,市值破 3000 亿,成国产 GPU 自主可控领军者。
07-1、公司核心团队
硬件负责人彭莉是 AMD 全球华人女技术领域的 “第一人”,作为 AMD 官方认证的顶尖科学家(Fellow),她曾担任高端 GPU “总设计师”(首席架构师),在显卡核心设计领域深耕 20 年以上;
软件负责人杨建则是 AMD 大中华地区技术圈的 “开先河者”(首位科学家 Fellow),履历横跨 AMD、海思两大芯片巨头,均曾任核心技术 “掌舵人”(首席架构师),20 年来专注大型芯片和显卡的软硬件整体设计,经验覆盖全产业链。

07-2、最新股权结构

08 AI芯片市场情况
AI 芯片广泛应用于云端、边缘端及终端,适配大模型训练(含预训练、后训练)与推理阶段:训练端重算力和互连通信,英伟达主导;推理端依场景差异化,云端需强算力,边缘 / 终端侧重功耗与时延,市场竞争充分。
当前训练需求占主导,中长期推理应用将规模化落地。国产厂商多从推理端切入,训练端国产替代率低,在海外出口管制背景下,高性能训练芯片厂商将受益于替代需求。
详细可见:


下方扫码直接加入:































热门跟贴