


生物毒素通常存在于世界各地的真菌、病毒、细菌、原生动物和传染性物质中。食品中的生物毒素主要来源于食品原材料、加工过程和储存条件等方面,如果食品中的生物毒素超标,会对人体健康造成潜在风险。因此,在食品安全领域,生物毒素的预测与预防是保证公众健康的重要环节之一。
机器学习作为人工智能的分支,近年来在多个领域展现了其强大的能力,尤其是在处理复杂数据模式和预测未知结果方面表现突出。在食品科学领域,其主要优势之一是它允许对复杂的生物学问题进行建模和预测,尽管这通常需要较高的计算能力和大量的数据集来支撑模型的学习过程。随着全球食品安全问题日益受到关注,传统的生物毒素预测方法因耗时长、操作繁琐以及成本高昂而逐渐显现出局限性。相比之下,机器学习技术提供了一种全新的解决方案。通过训练算法识别生物毒素的模式和特征,机器学习不仅可以提高预测的速度和准确性,还可以降低成本、实时监测。更重要的是,它还能帮助科学家们更深入地理解生物毒素的作用机制及其与环境因素之间的相互关系。
江南大学未来食品科学中心的丁浩晗、崔晓晖,江南大学人工智能与计算机学院韩瑜等探讨机器学习在食品领域生物毒素预测中的应用与展望,包括其基础理论、主要算法、模型性能评估以及在实际应用中遇到的挑战和未来的发展方向。此外,在文章的展望部分,还探讨机器学习技术在这一领域中的前沿趋势和发展方向,旨在为突破传统预测模型的性能极限提供坚实的理论基础和实践指导。这种系统化的分析不仅有助于推动学术研究的进步,也为实际应用提供了有价值的参考框架。

01
机器学习基础
1.1 机器学习的核心概念
机器学习是人工智能的一个核心领域,其核心目标是让计算机系统通过数据驱动的方式自动学习规律,并利用这些规律改进对任务的执行能力。从算法视角看,机器学习可被视为在给定训练数据的约束下,从大量候选模型中搜索最优解的过程——该解需在特定性能指标(如预测准确率或误差最小化)下表现最佳。但是这些算法会依赖于所收集数据的条件和大小。
机器学习系统通过从标注或未标注的训练数据中学习,构建能够自主完成特定任务的分析模型(如分类、聚类或回归)。其核心能力体现在:1)泛化能力:模型需在未见过的数据上保持预测准确性,例如在生物毒素检测中,需对新发现的毒素亚型(如新型产毒真菌代谢物)进行合理分类;2)适应性:通过增量学习或在线更新,模型可随新数据(如毒素数据库的扩展)动态优化性能,例如更新黄曲霉毒素预测模型以适应不同环境条件下的毒性变化。
如图1所示,机器学习的主要算法可分为监督学习和非监督学习。
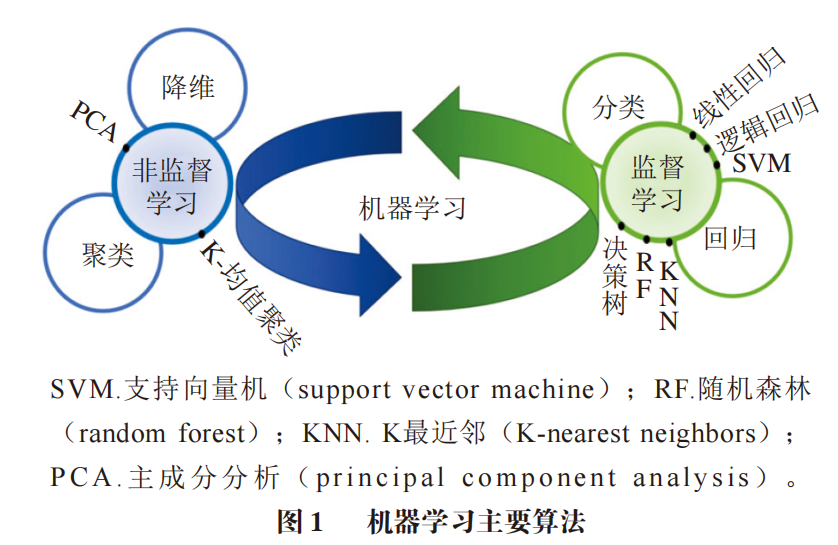
1.2 机器学习的主要算法
1.2.1 监督学习
监督学习算法是机器学习中最常见的一类,它们通过从标记的训练数据中学习,以预测未见过的数据的输出。一般来说,监督学习主要分为两种类型的任务:回归和分类。常见的方法主要有线性回归、逻辑回归、决策树、SVM、RF、KNN。
线性回归是一种用于预测连续数值的算法,用于查找一个或多个预测变量之间的线性关系。该模型假设因变量Y与自变量X之间存在线性关系,可以表示为方程(1):

式中:β0是截距项;β1、…、βn是各自变量的系数,表示自变量每变化一个单位,因变量预期将如何变化;ϵ是误差项,表示模型无法解释的随机变异。
以预测小麦中的黄曲霉毒素为例,其输入变量X1、X2、X3可分别为环境湿度、存储温度、存储时间;Y表示黄曲霉毒素的浓度,则该方程可表示为:

逻辑回归常用于二分类问题,主要用于评估各种预测变量(分类或连续)与二元结果(二分法)之间的关系。对于生物毒素预测,其变量可以是分类变量或连续变量,其中,连续变量可以是毒素的理化性质,如毒素分子质量、溶解度等,分类变量可以是毒素的类别或来源等。与决策树或SVM不同,逻辑回归有较出色的解释概率问题的能力,并且可以更新模型以轻松获取新数据。在生物毒素预测中,其核心优势在于能够通过概率输出解释变量对目标的影响,并灵活调整分类阈值。
决策树是一种通过树形结构进行分类或回归的机器学习模型,其内部节点代表输入数据特征的测试条件,叶节点代表最终的分类结果。从类别角度而言,它可以分为分类树和回归树。在生物毒素预测领域,分类树可用于二元或多元分类任务,如区分高毒性和低毒性,而回归树可用于预测连续纸,如毒素的半致死量。决策树的优势在于其易于解释,可以轻松处理功能之间的交互。在生物毒素预测领域,其分支可直观展示哪些特征对分类贡献最大。例如,若毒素来源(如产气荚膜梭菌)在根节点被优先选择,则说明该特征对毒性判断至关重要。
SVM是一种强大的分类算法,其核心原理是通过在特征空间中寻找最佳边界(超平面)最大化两类样本之间的间隔,从而实现对复杂数据的高效分类。由于SVM在解决一系列分类问题方面相对简单和灵活,即使在样本量相对有限的研究中,它也能独特地提供平衡的预测性能。因此,在生物毒素预测领域,SVM可用于高维数据处理,如生物毒素的分子结构、理化性质等。但是SVM在数学上很复杂,而且计算成本很高。例如,对于大规模毒素数据集(如环境毒素筛查的批量分析),可考虑利用GPU并行处理。
RF是一种基于集成学习的分类与回归方法,通过构建多棵决策树并聚合其预测结果,显著提升模型的泛化能力和鲁棒性。RF通常领先于SVM,是分类中许多问题的最佳算法。它具有快速、可扩展、抗噪能力强、不会过度拟合、易于解释和可视化等特点。在生物毒素预测领域,生物毒素实验数据常存在噪声(如测量误差、样本污染)或缺失值,RF通过袋外数据验证和多树聚合,可显著降低噪声对模型的影响。但RF也存在模型复杂、参数敏感与过拟合风险等缺点。例如,在处理处理10万 条毒素分子数据时,单机训练可能需数小时。针对该问题,可考虑采用分布式计算框架处理。
KNN是一种基于实例学习的分类与回归方法,其核心假设是“相似的样本在特征空间中彼此靠近”。该算法是模式识别领域中被广泛研究和分析的经典分类器之一。其优点包括无需训练过程、对数据分布无假设、简单直观以及能够处理多分类问题。例如,在生物毒素预测领域,KNN可直接扩展至多类别问题(如区分神经毒素、细胞毒素、肝毒素等),无需复杂调整。但其缺陷在于对数据规模和维度敏感,在处理不平衡数据集时可能表现不佳。例如,若某类毒素(如罕见的高毒性菌株)样本数量极少,KNN可能因少数样本的“邻近效应”导致分类偏差。针对该问题,可考虑对稀有毒素类别进行过采样(如SMOTE算法生成合成样本),或对多数类进行欠采样,缓解数据不平衡问题。
1.2.2 非监督学习
非监督学习算法是指在没有标签或输出的情况下从数据中学习的方法。其主要用于聚类、关联规则学习和降维。常见方法主要有K-均值以及PCA等。
K-均值是一种经典的无监督聚类算法,通过将数据划分为K 个簇,使得簇内样本相似度最大化、簇间差异最小化,已被广泛应用于生物毒素的分类研究。在生物毒素预测中,其核心功能包括将毒素样本分组成具有相似理化性质或毒性特征的簇,例如根据分子质量、溶解度、毒性强度或作用靶点等特征,将毒素分为不同毒性等级或亚型。K-均值算法计算复杂度较低,适合处理大规模高通量毒素数据(如基因组学或代谢组学数据)。尽管其在生物毒素分析中具有实用价值,但其固有缺陷可能显著影响结果可靠性。其初始质心的随机选择可能导致不同聚类结果。例如,若研究者在分析某类细菌毒素时,因初始质心选择差异导致同一毒素被错误归类为“高毒性”或“低毒性”簇,这会直接影响后续毒性预测的稳定性。针对该问题,可考虑通过特征工程(如标准化、降维)减少非关键特征对距离计算的干扰,或引入生物学先验知识(如已知毒素分类)指导初始化质心选择。
PCA是一种广泛应用于数据科学领域的降维技术。其核心思想是通过转换原始变量集到一组新的线性不相关的变量(PC),在保留关键特征的同时降低数据维度。在生物毒素预测中,PCA的核心价值在于处理高维毒性特征数据(如分子结构参数、基因表达谱、代谢组学数据等),并辅助后续的毒性分类或模式识别任务。例如,研究者可将毒素分子的数百个理化性质(如疏水性、电荷分布、分子指纹等)降维为少数PC,以简化模型训练或可视化毒性特征分布。PCA可将高维毒素数据投影到二维或三维空间,帮助研究者直观识别毒性亚型或毒性特征分布模式。例如,通过PCA二维图可区分神经毒素与细胞毒素的群集,为后续分类模型提供生物学假设。尽管PCA在生物毒素分析中具有实用价值,其固有缺陷可能限制其效果。PC是原始特征的线性组合,其解释性受限,高载荷(权重)并不直接对应生物学意义。例如,某PC可能由多个分子结构参数的复杂组合构成,研究者难以直接解释该成分与毒素毒性的关联机制。针对该问题,可考虑在降维后,通过特征载荷分析(如热图)关联PC与原始变量的生物学意义。此外,类似于人脸识别中的挑战,生物毒素的某些高维结构数据(如蛋白质三维结构或分子指纹矩阵)可能因强制转换为一维向量而丢失空间信息。例如,将二维蛋白质接触图转换为一维向量后,PCA可能无法有效捕捉关键的拓扑特征,导致降维后的毒性模式识别效果下降。针对该问题,可考虑采用保留空间信息的降维方法(如t分布随机邻域嵌入或均匀流形近似与投影),或使用深度学习自动提取毒性相关特征,避免PCA的线性假设限制。
在食品生物毒素预测中,监督学习与非监督学习的协同应用显著提升了预测的全面性与可靠性。其中,监督学习通过标注数据实现精准预测与任务导向决策,是实际应用的核心工具,非监督学习通过探索未知模式、简化数据结构及增强模型鲁棒性,为科学发现提供基础。两者结合使用,不仅优化了模型性能(如通过降维减少计算成本),更推动了从“预测结果”到“机制解析”的深度研究,为食品安全监测与毒素防控提供了系统性支持。
02
机器学习在食品生物毒素预测中的应用
机器学习在食品生物毒素预测领域具有广泛的应用,本节将分别从机器学习基于光谱分析以及图像识别的生物毒素预测展开详细论述。
2.1 基于光谱分析的生物毒素预测
机器学习模型可以通过学习光谱数据的特征,预测食品中是否存在生物毒素。这种方法的优点在于其高速度和低成本,适用于大规模的食品安全预测。光谱分析可以快速预测食品中的生物毒素。Zhang Pengjie等提出了一种新的结合了机器学习算法的拉曼光谱信号处理方法分类和预测有害物质。实验结果显示,经过多散射校正和多元散射校正-平滑预处理的拉曼光谱图在分类有害物质方面表现出色。Tavares等结合卫星图像数据和贝类毒素污染数据,利用时间序列预测模型预测贝类毒素。结果显示,将卫星数据特征整合到预测模型中可以显著提升预测性能。Tyska等提出使用近红外光谱(NIR)预测巴西玉米中的伏马毒素(FUM)和玉米赤霉烯酮(ZEN),定义3个回归模型,采用具有完全交叉验证的偏最小二乘回归算法作为内部验证,使用200个未知样品进行外部验证。最终结果表明,NIR适用于快速分析大量玉米样品的FUM和ZEN污染。
2.2 基于图像识别的生物毒素预测
图像识别技术可以分析食品的外观特征,机器学习模型通过学习这些特征,可以预测食品中生物毒素的存在。这种方法在预测食品腐败和污染方面具有潜在的应用价值。Aggarwal等提出使用梯度提升模型等机器学习算法来处理和分析图像数据,其中,通过荧光光谱仪采集的荧光碳点条形码阵列的图像数据被用作机器学习模型的输入特征,这些图像数据包含了毒素与碳点相互作用后的荧光强度变化信息。最终结果表明,该方法能够实现超灵敏的检测,成功地在实际食品样本中识别出了被柑橘霉素污染的样本,具有较高的准确性和灵敏度。Fernandez等提出利用2D卷积神经网络(CNN)通过化合物的图形图像来预测其毒性。最终结果表明,通过深度学习模型,成功实现了对化合物毒性的有效预测。该方法能够直接从化合物的分子结构图像中提取特征,并利用这些特征进行毒性分类。与传统方法相比,这种方法显著简化了毒性预测的流程,并在多个毒性数据集上表现出良好的预测性能。Davidson等使用来自卫星遥感图像识别技术预测有害藻华。具体来说,作者使用多个卫星传感器的数据,生成卫星叶绿素图像,将训练好的线性判别分类器应用于卫星图像,生成藻华风险地图。结果表明,该技术为有害藻华和生物毒素的预测提供了有力支持。
机器学习在食品毒素预测领域的应用广泛,除上述两部分外,还有一些其他的应用案例,具体案例如表1所示。

如表1所示,使用机器学习算法预测生物毒素在研究和应用中具有重要的价值,但传统模型具有一定的局限性,如对小样本数据敏感,对复杂非线性惯性建模能力不足等。例如,在熊超平的研究中,所构建预测模型的准确率仅有76.90%,且数据集只包含1 个省份1 年的数据,数据多样性不足,需要更多年份的数据来提升模型的泛化性。该研究也进一步论证了机器学习模型在处理小样本数据集时存在的局限性。基于此,本文在第3部分详细介绍了对于机器学习模型的优化和改进。
03
机器学习模型的优化和改进
传统机器学习在生物毒素预测领域应用广泛,但在模型性能,模型精度以及预测的准确性方面仍存在一些问题,现有研究针对这些问题提出了机器学习在生物毒素预测领域的改进和优化。
3.1 特征选择
在食品生物毒素预测中,模型性能高度依赖数据特征的质量、相关性及冗余性。由于实际数据常包含大量冗余或噪声特征,特征选择技术可系统筛选出与目标变量(如毒性强度或毒素类型)强相关的最优特征子集,从而提升模型效率、精度及可解释性。
3.1.1 过滤式方法
食品生物毒素预测中,基于特征的方差、信息增益或互信息可以帮助筛选出与生物毒素存在密切相关的特征。例如,研究表明,基于特征的方差筛选可以有效降低多余数据对模型的干扰,保留生物毒素种类、浓度等关键信息,使得机器学习模型能够更专注于特定的生物毒素分类和定量预测。在Cruz等的研究中,过滤式方法被用于筛选出与贝类毒素污染高度相关的特征变量,以提高预测模型的性能。最终,这些经过筛选的特征显著提高了模型的准确性,使其能够更可靠地预测污染事件。在Shao Chuange等的研究中,方差筛选作为过滤式方法,用于识别与香蕉枯萎病真菌毒素产生密切相关的特征变量。最终,方差筛选帮助优化了特征集,提高了用于预测香蕉植株受真菌毒素影响程度的模型的准确性。在Mayr等的研究中,信息增益作为过滤式特征选择方法用于选择与毒性预测高度相关的化学特征,通过使用信息增益筛选的特征有效提升了模型的准确性和预测能力,为毒性筛查提供了关键支持。在Idakwo等的研究中,信息增益作为一种过滤式特征选择方法,用于从大量分子描述符中筛选出与毒性预测高度相关的特征。最终,信息增益筛选的特征有效提升了模型的预测准确性,使得模型在化学毒性预测任务中表现出更高的稳定性和准确性。
3.1.2 包裹式方法
递归特征消除(RFE)在食品生物毒素预测中具有潜在应用价值。通过逐步去除不重要的特征,RFE可以帮助筛选出对生物毒素分类预测贡献最大的一组特征。例如,Rathore等在预测肽毒性时,使用各种机器学习分类器创建预测模型,并使用特征选择技术来选择最相关的特征,最终结果表明,当使用基于树的特征选择方法选择的特征时,生成结果所需的时间较少。在Almoujahed等的研究中,RFE用于选择对预测小麦中DON污染最有贡献的光谱特征。最终,RFE选择的特征使模型在计算效率和准确性方面均有所提升,为快速筛查粮食中的DON污染提供了实用性更强的方案。
3.1.3 嵌入式方法
正则化方法(如L1、L2正则化)在模型训练中同时进行特征选择,在高维数据的食品生物毒素预测任务中,L1正则化有助于去除冗余特征,增强模型的解释性。正则化方法在神经网络生物毒素预测模型中应用广泛,可以自动优化模型权重,从而提升预测的可靠性和泛化能力。在Jin Xuebo等的研究中,正则化方法被应用于预测水稻供应链中镉含量的深度网络模型,以减小噪声影响和防止过拟合。实验结果显示,正则化后的模型在镉含量预测任务中表现出更高的预测准确性和稳定性。在Yamasaki等的研究中,正则化方法(使用Elastic Net)用于建立一个预测番茄加工食品中农药残留处理因子的模型。实验结果显示,该模型在训练和测试数据上均表现出较高的预测精度,为无需实际加工实验便能评估农药残留风险提供了有力支持。
对于分析生物毒素特征而言,通过特征选择不仅能够减少模型的复杂度,提高模型的准确率和泛化能力,还能降低模型训练时间,并提高模型的可解释性。
3.2 超参数调优
在食品生物毒素预测中,模型需在高精度与快速响应之间取得平衡,而超参数的合理设置是实现这一目标的核心手段。超参数(如学习率、树深度、正则化系数等)直接影响模型对数据的拟合能力与泛化性能,其优化可显著提升不同毒素类型(如黄曲霉毒素、贝类毒素)的预测效果。其核心方法包括网格搜索、随机搜索、贝叶斯优化、进化算法。
3.2.1 网格搜索
在生物毒素预测的分类模型中,网格搜索可以用来系统地优化关键超参数,例如树模型中的深度、叶节点数等,其全面性适合于生物毒素预测所需的高精度模型。例如,Hemmerich等结合了多种机器学习方法和结构警报技术来构建预测模型,用于预测线粒体毒性。最终表明,深度学习模型和梯度提升模型在训练和测试集上都有很好的表现,并且对不同算法或架构进行网格搜索可以提高可预测性。
3.2.2 随机搜索
当生物毒素预测模型中的数据量较大时,随机搜索通过在更广泛的超参数组合中进行探索,能够以相对较低的计算成本找到有效的参数设置。Xu Youjun等使用深度学习方法构建了回归和多分类模型,用于预测化合物的急性口服毒性。在超参数调优方面,作者选择了随机搜索,主要原因在于随机搜索在处理高维、复杂参数空间时的效率和效果。而在生物毒素预测方面,其模型通常涉及大量超参数,因此,使用随机搜索能高效探索复杂参数空间,找到性能较好的超参数组合。
3.2.3 贝叶斯优化
贝叶斯优化基于每一次超参数选择的结果逐步优化模型参数。食品生物毒素预测中,通过贝叶斯优化调整模型参数,可显著减少生物毒素分类误差。例如,在预测AFL和重金属毒素浓度时,贝叶斯优化提高了模型的检出率和准确性。在Liu Ningjing等的研究中,贝叶斯优化用于优化AFL和FUM污染预测模型(PREMA和PREFUM)的结构,以提升预测玉米中这两类毒素污染的准确性。优化后的模型在内外部验证中表现出较高的预测准确性,PREMA和PREFUM分别达到了83%和76%的准确性,有效提高了对生物毒素污染的早期预警能力,为食品安全管控提供了可靠的工具。在Setiya等的研究中,贝叶斯优化用于优化MolToxPred模型中的超参数,以提高小分子毒性预测的准确性。优化后的模型在测试集上达到了87.76%的AUC值,而在外部验证集上达到了88.84%的AUC值,有效提升了预测毒性分子的能力。
3.2.4 进化算法
进化算法模拟自然选择过程,通过迭代找到最优参数组合,适用于食品生物毒素预测中涉及复杂特征的任务。研究发现,使用遗传算法优化生物毒素预测模型参数,能使模型适应不同的预测环境和生物毒素种类,提高泛化能力。在Wawrzyniak等的研究中,进化算法(具体为遗传算法)被应用于优化B样条模型,以预测大麦储存过程中霉菌的增长情况。实验结果显示,该模型在学习和验证数据集上表现优异,相关系数达到0.94,均方根误差仅为0.28。这一方法为谷物储存管理系统提供了有效的霉菌监控和预测工具,有助于保障食品储存安全。在Henderson等的研究中,遗传算法被用于优化神经网络的结构和超参数,以预测花生中的AFL污染。该方法使得优化后的神经网络模型在训练、测试和验证数据集上均表现出更高的预测准确性,相比传统手动调整参数的方法预测性能显著提高。
超参数调优是食品生物毒素预测中不可或缺的步骤,其通过系统性方法(如贝叶斯优化)与领域知识结合,显著提升模型在精度、速度与泛化性上的表现。合理选择调优策略(如计算资源有限时采用随机搜索,复杂模型使用贝叶斯优化和进化算法)是实现高效预测的关键。
3.3 集成学习
在食品生物毒素预测中,单一模型可能因数据高噪声、特征冗余或局部过拟合导致性能受限。集成学习通过组合多个基模型(如决策树、SVM或神经网络),显著提升模型的准确性和稳定性,同时降低过拟合与欠拟合风险。其核心方法包括Bagging、自适应算法(Boosting)、堆叠泛化算法(Stacking)。
3.3.1 Bagging
通过对生物毒素数据集进行有放回的随机采样,Bagging技术可构建多个子数据集,训练多个基学习器(如决策树、RF等),最终对多个模型的结果进行平均或投票,适用于生物毒素预测的数据集样本数量有限且特征维度较高时。Sahibzada等采用Bagging方法集成RF和深度神经网络,根据酶的毒素降解能力对其进行分类,实现高达95%的预测精度,有效保障了模型的高准确性。该方法为环境生物技术、食品营养与健康等领域的应用提供了宝贵的工具和资源。Kos等使用了Bagging决策树来进行基于毒素污染阈值对玉米和花生样本的分类任务,结果表明,Bagged模型在1 750 µg/kg和500 µg/kg的污染阈值下,达到了79%和85%的分类准确率,有效提升了对食品中生物毒素污染的预测效果。
3.3.2 Boosting
Boosting通过构建一系列模型,每个模型关注前一个模型中错误分类的样本,适用于生物毒素预测中预测难度较高的生物毒素或低浓度生物毒素的识别。例如,Li Huanhuan等在Hg2+残留分析模型中通过增强表面增强拉曼光谱信号,提高了模型的预测精度和稳定性。相比其他模型,AdaBoost在多次学习中对预测误差进行补偿,从而有效提升了模型在食品中重金属预测中的应用效果。在Castano-Duque等的研究中,Boosting方法用于预测伊利诺伊州玉米中的AFL和FUM污染水平。通过使用GBM结合历史气象数据与生物毒素污染数据,该方法在天气事件与生物毒素污染风险之间建立了显著的关联,整体准确率达到94%。同样地,在Branstad-Spates等的研究中也使用了GBM模型去预测美国艾奥瓦州玉米中的AFL污染水平。模型揭示了植被指数和土壤饱和导水率等特征对生物毒素污染的影响,有助于在作物生长期预测生物毒素风险,为农民采取早期防控措施提供了参考。
3.3.3 Stacking
Stacking通过训练多个基学习器(如神经网络、SVM等),并使用一个元学习器(如逻辑回归)整合这些学习器的预测结果。研究表明,Stacking在食品生物毒素的预测和定量分析中表现出优异的性能,可以综合多个算法的优势,在复杂的生物毒素数据集上实现更高的准确性和泛化性。例如,Chen Zewei等开发了一种名为T1SEstacker的3 层堆叠模型,用于预测细菌I型分泌蛋白。该模型基于C末端非重复毒素基序序列特征,并结合多种机器学习技术来提高预测的准确性和可靠性。通过这种创新方法,作者成功实现了对I型分泌蛋白的高效预测,显著提升了预测性能,为研究细菌的致病机制和开发防治策略提供了有力工具。Beltrán等提出采用集成机器学习方法,通过堆叠分类器对多种机器学习算法集成,开发了MultiToxPred 1.0工具用于预测蛋白质毒素。该工具的预测性能通过敏感性、准确性、精确度和F1分数等指标进行了评估,并通过AUC进一步验证了其有效性。最终,证实MultiToxPred 1.0作为一个现代的Web应用程序,能够为用户提供从0到1的概率评分,帮助快速预测和分类潜在的蛋白毒素。
集成学习通过模型组合策略,为食品生物毒素预测提供了高鲁棒性与泛化能力的解决方案。合理选择方法(如Bagging处理高维数据、Boosting优化小样本场景)并结合领域知识(如毒素分子机制约束),可进一步释放其在食品安全监测中的潜力。未来研究可探索深度学习与传统集成方法的混合架构(如神经网络Stacking),以应对复杂毒素数据的挑战。
通过对特征选择、超参数调优和集成学习的综合应用,可以显著优化和改进机器学习模型的性能,从而更好地在食品生物毒素预测应用领域发挥作用。
04
面临的挑战与未来发展
在机器学习技术应用于食品生物毒素预测领域的研究进程中,尽管存在诸多亟待解决的挑战,但近10 年间,海量多维度数据的持续累积、高性能计算能力的显著提升以及多种机器学习算法的创新与应用,共同为该研究方向开辟了新的路径,有力地推动了食品健康安全体系的完善与发展。
本节主要从数据质量与可用性、模型泛化、实时监测以及跨学科协同4 个角度探讨,如图2所示。

4.1 数据质量与可用性:多模态数据融合与理论框架构建
当前生物毒素预测面临数据异构性、稀疏性及隐私保护的三重困境。未来研究需从理论层面构建多模态数据融合框架,通过开发跨域特征对齐算法,解决光谱、代谢组学与毒理学数据间的语义鸿沟。例如,Zheng Zhen等提出通过学习跨域特征对齐来提高跨域医学图像分析的性能。具体来说,他们引入了一种基于分类器一致性的特征对齐策略,旨在学习具有判别性和域不变性的特征表示。这种方法通过最小化同一类别样本在不同域之间的特征分布差异,从而增强模型的泛化能力和鲁棒性。此外,作者还结合了特征提取器和分类器的组合,以进一步提高模型的性能。实验结果表明,该方法在多个跨域医学图像分析任务上取得了显著的性能提升,证明了其有效性和优越性,这为将跨域特征对齐引入食品毒素预测领域提供了理论基础。针对高维稀疏数据,应充分考虑高维数据的几何信息。例如,Sha Lingdao等提出了一种结合图拉普拉斯正则化与稀疏编码的方法,用于解决图像恢复和表示的问题。该方法旨在通过图拉普拉斯正则化捕捉图像的结构信息,同时利用稀疏编码来获取图像稀疏表示,从而提高图像恢复的质量和鲁棒性。实验结果表明,该方法在多种图像恢复任务中取得了良好的性能,能够有效地去除图像中的噪声并恢复图像的细节。因此,在食品生物毒素预测领域,应发展基于稀疏编码的正则化理论,结合自适应稀疏惩罚项与几何深度学习方法,提升模型在低样本量场景下的泛化边界。在隐私计算领域,需突破联邦学习的同构性假设,发展异构联邦学习理论。同态加密可以对加密数据执行不同操作,而无需事先解密,该加密技术可针对不同的目标,适用于不同的系统。差分隐私通过添加所需的噪声量来保护统计或实时数据,同时在隐私和准确性之间保持健康的权衡。通过差分隐私与同态加密的联合优化,可以实现数据价值挖掘与隐私保护的帕累托最优。
4.2 模型泛化能力:从经验驱动到理论驱动的范式转变
突破模型泛化瓶颈需构建基于因果推理的机器学习理论体系。Kliangkhlao等提出了一种因果贝叶斯网络(CBN)模型,旨在帮助理解农业供应链中的市场动态。该模型能够对市场参与者的行为和决策进行建模,从而解释价格形成机制以及市场参与者的决策行为。通过这种方式,CBN模型为市场参与者提供了有用的见解,帮助他们理解市场的运作方式,并做出更明智的决策。因此,在食品生物毒素预测领域,建议发展CBN,通过嵌入毒理学先验知识(如剂量-效应关系、代谢路径网络),建立可解释的因果效应模型。在算法层面,需探索元学习与迁移学习的理论融合。例如,Chen Jianguo等提出了一种域自适应密度聚类(DADC)算法,旨在解决具有不同密度分布的数据的聚类问题。实验结果表明,与其他比较算法相比,DADC算法在具有不同密度分布、均衡分布和多个域密度最大值的数据上可以获得更合理的聚类结果。同时,由于其对参数需求较少且具有非迭代性质,DADC算法计算复杂度较低,适用于大规模数据的聚类。因此,在食品生物毒素预测领域,应该开发跨物种、跨环境的毒素预测迁移框架,通过领域自适应算法减少数据分布偏移的影响。
4.3 实时监测:边缘智能与物理-数字融合系统
下一代实时监测系统需构建“感知-计算-决策”的闭环理论体系。在技术架构上,需发展基于轻量化神经网络的边缘智能框架。例如,Shen Hua等提出了一种轻量级CNN L-Net,旨在解决深度学习模型在低计算能力设备(如物联网设备)上应用时面临的挑战,特别是通道间相互作用差异和梯度消失的问题。实验结果表明,L-Net在CIFAR-10数据集和自定义的苹果树叶片疾病数据集上都取得了优异的性能,这为将轻量级CNN引入食品生物毒素领域提供了技术支撑。在数据层面,需建立多源异构传感器数据的时空对齐理论,实现毒素风险的动态预测。例如,Wang Xiaofeng等提出了一种基于深度学习的多源异构信息融合框架,用于解决铣削过程中表面质量在线监测的问题。该框架旨在整合来自不同传感器和数据源的多源异构信息,以提高监测的准确性和及时性。因此,在食品生物毒素预测领域,应充分利用多源异构信息,提高食品生物毒素动态预测的准确性和及时性,为食品安全提供更有效的保障。
4.4 跨学科协同:理论-技术-伦理的三维创新体系
构建跨学科研究范式需突破传统学科边界,发展“计算毒理学-食品组学-机器学习”的交叉理论体系。在过去的几年里,伦理学家和其他专家提出了一系列与人工智能相关的担忧,这些担忧主要可以分为3 类:公平、问责和透明度。因此,应建立标准化的毒素预测评估指标体系,并制定数据共享的伦理准则与技术标准。在方法论层面,需发展多智能体强化学习框架,模拟不同学科研究者的协作行为,通过博弈论优化跨团队资源分配与知识共享机制。同时,应建立机器学习模型的可解释性理论框架,满足食品监管领域的透明性要求。
05
结语
机器学习技术在食品生物毒素预测领域展现出了显著的潜力和实际应用价值。本文总结了机器学习模型在处理复杂数据和识别模式方面的能力,为食品生物毒素的早期识别和预测提供了强有力的工具。同时阐述了机器学习技术在特征选择、超参数调优和集成学习方法的潜力,这些方法将显著提高模型的准确性和鲁棒性,使得预测结果更加可靠。尽管面临数据隐私、模型解释性和实时监测等挑战,机器学习算法在食品生物毒素预测的应用不仅有助于保护消费者健康,也对环境保护和可持续发展具有重要意义。随着机器学习技术的不断进步和创新,预计未来其将在食品安全监测和环境保护中发挥更加重要的作用,实现更精准、快速的预测,为食品中生物毒素的精准预测和在线预测提供参考。
第一作者:

丁浩晗讲师
江南大学未来食品科学中心
丁浩晗博士,于2021年12月荣获新西兰奥克兰大学博士学位,随后加盟江南大学未来食品科学中心陈坚院士团队崔晓晖教授课题组的食品计算与风味组学实验室。主要研究方向为图像处理、人工智能以及工业智能化在乳制品领域的应用。曾担任《Foods》和《食品科学》等期刊的专栏主编,并作为多个国内外知名学术期刊的审稿人。以第一作者在国内外高水平学术期刊上发表论文20余篇,还申请了9 项发明专利和7 项软件著作权,并多次在国际会议上进行口头或海报展示。目前正担任“十四五”国家重点研发计划项目“食品全程全息风险感知及防控体系构建与应用示范”(2022YFF1101100)和“十四五”国家重点研发计划政府间国际科技创新合作项目“基于图像分析技术的奶粉品质在线检测关键技术研究”(2024YFF0199500)的子课题负责人。
通信作者:

崔晓晖教授
武汉大学国家网络安全学院
崔晓晖教授,博士毕业于美国路易斯维尔大学,曾担任美国能源部橡树岭国家实验室研究员以及美国路易斯维尔大学讲座教授。目前担任武汉大学国家网络安全学院二级教授、江南大学未来食品科学中心陈坚院士团队特聘教授以及嘉兴未来食品研究院特聘研究员。长期从事人工智能、大数据、区块链技术在食品领域的应用与交叉研究。在国内外高水平期刊发表论文二百余篇。主持了“十三五”国家重点研发计划“食品安全大数据关键技术研究”项目,并担任“十四五”国家重点研发计划“食品全程全息风险感知及防控体系构建与应用示范”中的课题负责人。目前还担任“十四五”国家重点研发计划政府间国际科技创新合作项目“基于图像分析技术的奶粉品质在线检测关键技术研究”(2024YFF0199500)的项目负责人。共主持食品安全、大数据、人工智能等方面的24 项国家自然基金、军委装备重点基金等项目。
本文《机器学习在食品安全领域生物毒素预测中的应用与展望》来源于《食品科学》2025年46卷第15期16-26页,作者:丁浩晗,韩瑜,宋晓东,崔晓晖,黄骅迪,董冠军,王龙,乌日娜。DOI:10.7506/spkx1002-6630-20250206-016。点击下方阅读原文即可查看文章相关信息。
实习编辑:李雄;责任编辑:张睿梅。点击下方阅读原文即可查看全文。图片来源于文章原文及摄图网






















热门跟贴