

哈喽,大家好,我是小方,今天,我们主要来看看最近AI学术圈里一个炸锅的消息——视频理解领域的“高考卷”刚刚迎来了史诗级更新。


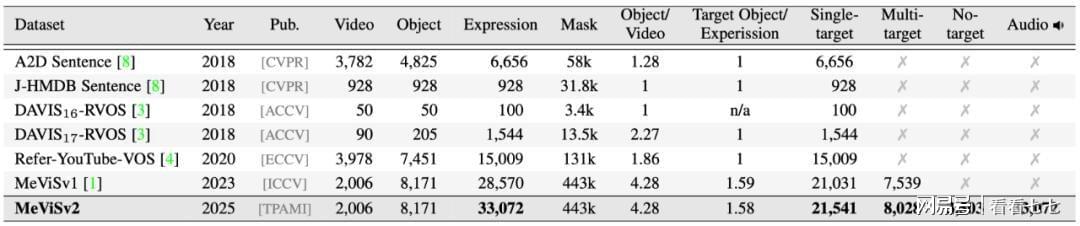
MeViS的第一代就硬核地纠正了这一点,它立下三条铁律:第一,语言描述必须围绕“运动”,比如“飞走的鸟”、“滚过来的球”,禁止用容易识别的静态特征作弊;第二,场景必须复杂,一群外观相似的物体挤在一起;第三,视频要足够长,平均13秒,目标持续近11秒,考验模型的“长时记忆力”,这样一来,模型被迫必须认真“看视频”,分析动态,才能找到目标,正是这种高难度,让MeViSv1吸引了全球近千支队伍挑战,成为了领域内的标杆。

如果说MeViSv1是出了道难题,那MeViSv2简直就是构建了一个贴近真实的“复杂世界”,它的升级主要体现在三个方面,个个直指当前AI的软肋。


第二,任务拓展:一个数据集覆盖四大核心战场。MeViSv2一次性支持四大任务:指向性视频分割(RVOS)、音频引导分割(AVOS)、指向性多目标跟踪(RMOT)和运动描述生成(RMEG)。

第三,规模与机制升维:专治AI“幻觉”和“逻辑短路”。除了数量增长,MeViSv2新增了两类“杀手级”语句。一类是“运动推理语句”,另一类是“无目标语句”,描述一个视频中根本不存在的动作,专门用来整治那些不懂装懂、强行输出一个目标的AI“幻觉”问题,这要求AI必须具备逻辑判断和说“不”的能力。

面对如此高难度的数据集,原来的模型明显不够用了。研究团队也同步提出了一个新的基线模型LMPM++,这个模型的思路很巧妙,它不再让AI一帧帧硬看视频,而是先把视频里可能的物体都找出来,变成一组简洁的“对象快照”,然后喂给大语言模型(LLM)去分析,LLM擅长逻辑推理,可以跨时间线把动作的前因后果串起来。


此外,它的发布正与国内多模态大模型的研发热潮形成共振,越来越多的科技公司意识到,下一阶段AI的竞争,不仅是“看图说话”,更是“看动态视频并深度理解”。

MeViSv2提供的海量、高质量、强逻辑标注的数据,将成为训练和检验这些大模型视频理解能力的核心资源,它从学术界抛出的一块“试金石”,很可能在未来一两年内,催生出真正能理解复杂动态视觉世界的新一代AI应用。

MeViSv2的发布,无疑为多模态视频理解领域树立了一座新的灯塔,它告诉我们,真正的视频智能,必须能看懂动态、理解因果、抵抗干扰。

前路虽难,但每一次基准的刷新,都是向着让AI更懂我们所在世界迈出的坚实一步,这场关于“动态视界”的竞赛,刚刚进入最精彩的章节。




















热门跟贴