


前两天看到B站百大up主LKs发了一期Pocket 4P评测的视频,谈了一个非常有趣的问题,叫做:买了博主同款设备,为什么拍的还是不好看。
他给出了一个公式:
成片质量 = 相机参数(P) × (拍摄人变量(S) + 相机易用性(U)) × (环境因子(E) + 天气因子(W))

意思是:相机参数再好,最终乘以的是你的技术和相机的易用性。设备只是乘数,人才是被乘数。同样设备到了不同人手里,出来的东西天差地别。
我看完之后蛮有感触的,因为AI视频领域正在发生完全一样的事。
字节的Seedance 2.0、快手的Kling 3.0、谷歌的Veo 3.1,模型一个比一个强。曾经封神的Sora,现在都没什么人讨论了。但你打开B站看看,用同样模型做出来的视频,质量差距大得离谱。有人做出来像电影片段,有人做出来像PPT配了动效。
其实和使用所有AI工具类似,当AI把基本的生成能力磨平之后,真正差异体现在领域知识上。比如所有人都能用AI Coding去做产品,但是做什么产品,或者说知道一个好产品如何产生的人会能把这件事执行得更好。而以AI视频来说,真正懂动画和电影领域工作流,具备相应审美的人才能做出更好的作品。
所以,你常常会发现,当大家用的模型都一致了,真正制约生产力的瓶颈又回到了人身上。
而这次,在体验了两天的oiioii之后,我又产生了些不同的想法。先看一个成品。我只输入了一个剧情的想法,OiiOii帮我做出来的4分多钟的短片:
这是怎么从一句话变成一部完整动画的?接下来慢慢说。
一个AI视频的质量公式
我自己拆了一个AI视频的质量公式:

M(模型能力)这个变量,2026年已经在快速拉平。大家都能用Seedance 2.0,都能用Kling 3.0,画面质量的差距在缩小。
真正拉开差距的,是S、U、D、C这四个变量。
而这四个变量,恰好就是大多数AI视频工具不管的地方。它们给你一个强大的模型(M拉满),然后把S、D、C全部甩给你。相当于给你一台顶配相机,但拍摄技术、构图、找光全靠你自己。
我在豆瓣标记看过的影视剧超过2000部。自己从来没拍过东西,但片子看多了,对一些导演的工作方式印象很深。
比如希区柯克,他出了名的要把每一个镜头都画成详细的分镜稿才开拍。他到了片场经常觉得无聊。因为在他看来,电影在画分镜的时候就已经拍完了,剩下的只是执行。
分镜决定的不是画面好不好看,而是故事怎么讲、节奏怎么走。 它掌控着观众的情绪走向。这就是公式里D这个变量的份量。
直到我用了OiiOii,我觉得终于有一个AI视频工具认真对待这件事了。
OiiOii:一句话雇7个AI员工
OiiOii是一个AI动画创作工具,去年底内测的时候10万人排队,今年4月正式上线,据报道已有超过20万创作者在用。
它跟其他AI视频工具最大的区别在于,它做的不是一个5-10秒的单镜头。它从一句话开始,帮你做出一整部1分钟以上的叙事动画。
怎么做到的?OiiOii搞了一个7人虚拟动画团队。每个人都是一个专业化的AI Agent,各司其职:

回到公式:OiiOii做的事情,是用7个AI员工把S、U、D、C四个变量同时拉高。 你的创作能力不够?编剧和分镜师帮你。你不会保持一致性?角色设计师和艺术总监帮你。工具不好用?一句话就能启动整条流水线。
这套打法比单纯把工具做得更易用要狠得多。别的工具是让你少干一点活,OiiOii是直接帮你干完。
实测:一句话到成片的完整流程
说到这里可能有点抽象,直接看我的实测。
我给OiiOii输入了一句话:「一对恋人在星空下的天文馆里起舞,周围的场景像走进了一幅油画,色彩梦幻,充满不真实的浪漫感。」

这句话的灵感是《La La Land》里两个场景的混合。一个是Mia和Sebastian在洛杉矶天文馆里悬浮起舞的那段星空。另一个是片尾两人在酒吧重逢后,脑海里想象的那段「如果当初我们在一起」的幻想片段,视觉上像直接走进了一幅画。我想用这两个画面的意境做底色,看OiiOii能延展出一个什么样的新故事。
然后就发生了一件蛮有意思的事。
下面拆开说每一步。
艺术总监接单,编剧写剧本
输入那句话之后,艺术总监先接单,提取了核心要素:星空天文馆、起舞的恋人、油画质感、梦幻浪漫。然后编剧Agent自动生成了一个完整故事。
两个角色: 陆星河(28岁天体物理研究员,理性主义者)和林梦影(26岁,感性的艺术灵魂)。故事发生在一个即将闭馆的天文馆里,讲的是理性与感性的碰撞和和解。
我只说了一句话,它给我写了一个有人物弧光的完整剧本。

角色设计师锁定外观
角色设计师根据剧本为两个角色生成了主图和三视图概念图。这一步的意义是锁定角色外观,确保后面19个分镜里角色不会变脸。

场景设计师搭建4个场景
场景设计师搭建了4个场景,每个场景都有多角度视图:
星语天文馆主放映厅(常规态)
天文馆设备维修室
天文馆生锈天台
梦幻油画星空大厅(极光态)
多角度视图的意义和角色三视图一样:保证不同镜头里同一个场景看起来是一致的。

分镜师拆出19个专业分镜
然后是重头戏。分镜师把整个故事拆成了19个分镜。
每个分镜都有专业的镜头语言:medium shot、wide shot、close-up、Dutch angle、俯拍,运镜方向、氛围光影全部写好了。分镜师还给了监修思路,比如在高潮段落特意增加了天象仪启动时「机械咆哮」与「光影狂欢」的细节衔接,避免角色在流动光影中产生空间瞬移感。

生成视频 + 音效 + 合成
分镜确认后,动画师开始逐个分镜生成视频。用的是Seedance 2.0模型,Pro模式,可以选720p或480p。

视频生成完之后,音效工程师用Suno生成了背景音乐,自动匹配叙事节奏。

最后艺术总监把所有素材合成为最终视频,可以下载720p或1080p高清版。

全流程总览
从一句话到成片,整个工作流长这样:

对照公式看一下这个过程:
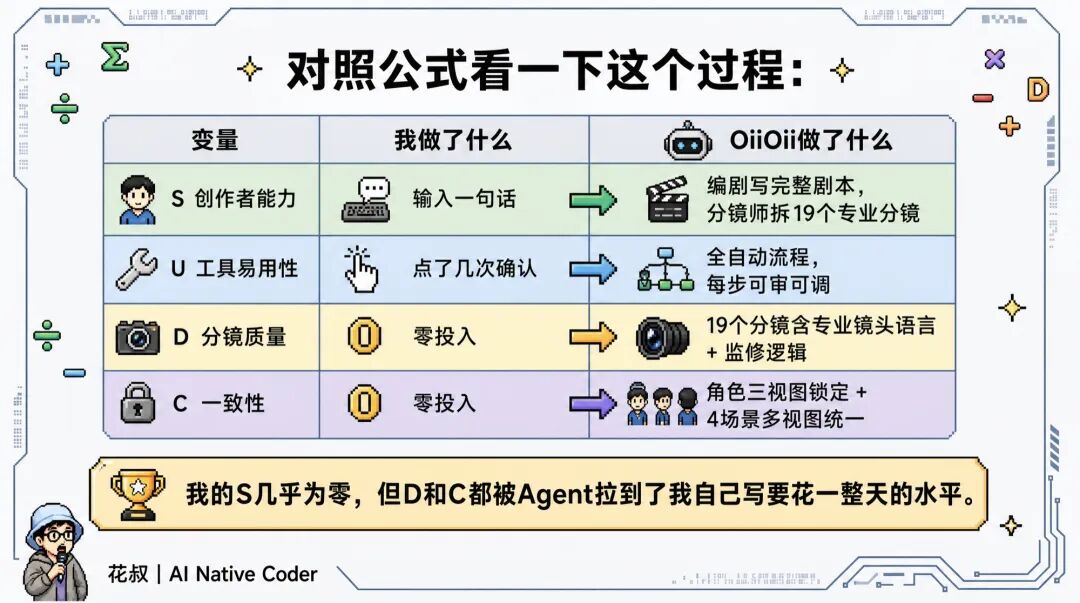
我的S几乎为零,但D和C都被Agent拉到了我自己写要花一整天的水平。
分镜三板斧:想做得更好,工具不挡路
上面是全自动模式的效果。但OiiOii真正让我觉得有意思的,是它在自动化之外还保留了精确控制的能力。
第一板斧:自动化分镜,不用再四处扒提示词了
用过AI视频工具的人都知道,最痛苦的不是等生成,是写提示词。一个30秒的视频拆成6个镜头,每个镜头写一段详细的英文提示词,光这一步就得磨一两个小时。
OiiOii的做法是:你不用写。编剧Agent写剧本,分镜师Agent拆镜头写提示词,全自动。
按我的理解,其实是因为OiiOii对这些影视制作工作流中不同角色的技能以及各类AI模型的能力有充足的领域认知,所以,他们把这变成了一个类似skill的东西,植入在了视频创作的工作流中。
第二板斧:自由画布模式,从参考图到成片的可控玩法
自动分镜够省心,但如果你心里已经有了一个具体的视觉参考呢?比如想复刻某个B站爆款的风格。
这就是自由画布模式的价值。点开任意一个分镜,你会看到分段式的提示词,清楚地分成画面描述、角色动作、镜头运动、氛围光影几个模块。Agent把底牌全露出来了。觉得角色表情不对?改表情那一栏。觉得镜头太远?改镜头运动那一栏。
画布模式支持三种操作方式:
全自动:完全交给Agent,你只管审片
半自动:投喂一张图,告诉Agent你想要什么
手搓:自己写提示词,完全手动控制
AI视频工具最实际的应用场景之一,就是复刻爆款。我决定拿OiiOii测一下这件事。
挑的是B站最近最火的「地牢酒馆」系列——第一视角进入地牢小酒馆,每集来一个奇怪生物喝酒,互动诡异又好笑。单集543万播放、32万点赞,是2026年AI视频赛道最值得研究的爆款样本之一。

我做了一个改编:把酒馆里的客人换成街头霸王里的角色,看OiiOii能不能在保留原作风格的基础上,做出新的故事。
先要选情绪关键词。OiiOii给了冲突、浪漫、恐怖、搞笑、欲望几个选项,每个都对应不同的叙事路径。地牢酒馆的精髓是荒诞反应,所以我选了「搞笑」。

然后遇到了一个小插曲。直接输入「街头霸王角色来酒馆」会被版权检测拦截。我换成原创设定描述(红头巾武术家、巨型摔角手、绿皮丛林战士这类),就过了。这其实是好事,原创设定比直接借用IP更适合做长期内容。
接下来角色设计师给5个角色都做了主图+三视图,每个角色之间风格统一,但形象有明显差异。

分镜师拆了5个镜头,每个角色一段互动。提示词的颗粒度让我有点惊讶,精确到0-2秒、2-4秒、4-7秒的动作分解,连「金币掉桌上的反弹路径」这种细节都写了。

视频生成阶段,5个分镜并行渲染,差不多5-6分钟全部出来。最后合成的视频比我预想的好,第一视角的代入感和原作很像,角色互动也有荒诞喜剧的感觉。
整个过程没有手写一个英文提示词。我只做了三件事:写一段中文故事描述、选情绪关键词、改了几句被版权拦截的描述。剩下的全是Agent在做。
第三板斧:把视频生成的黑盒展开
这个功能是我觉得OiiOii分镜能力最强的地方,也是99%的用户没注意到的。
传统AI视频工具的体验是:你写一段提示词,几分钟后吐出一个5秒的视频。中间发生了什么、画面怎么从开头变到结尾、想改某一帧怎么改,你都不知道。从提示词直接到视频,是个黑盒。
OiiOii把这个黑盒拆开了。
每个镜头其实是由多张关键帧构成的。 你可以对整个镜头做整体调整——改提示词、换模型、换画布比例,让整段画面跟着变。

也可以展开它,对镜头里任意一张关键帧单独修改。

视频节奏的每一个变化——动作的起势和完成、镜头的推近和拉远、情绪的转折——都是由这些关键帧的差异决定的。能调每一帧,就意味着你能掌握视频的每一秒。
反过来也行,从已有的分镜里任意勾选几个,组合成一段新的视频。
你对视频的控制颗粒度,从一整个镜头变成了一帧一帧。 不满意不用重来整个镜头,只改不满意的那一小段。
这背后还有一个常被忽略的好处:省钱。 AI视频模型现在真挺贵的,一个高清镜头生成成本几块到十几块不等,60秒的叙事动画动辄几十块起步。如果按传统工具的方式,一个不满意就重做整个镜头,废镜头的钱够你再做半部片子。分镜让创作过程专业的同时,也让执行节奏和最终成本变得可控——这其实是普通人能持续用AI做视频的前提。
用公式的语言说:画布模式和镜头拆分,让有能力的创作者可以主动拉高S和D这两个变量。 全自动已经给了一个不错的底线,想做得更好,工具也不会挡你的路。
回到公式
AI视频成片质量 = M × (S + U) × (D + C)
OiiOii没有在M(模型)上做出独家优势,Seedance 2.0别的工具也能用。但它用7个专业化的AI Agent,同时拉高了U、D、C三个变量,还帮你补了S。这是M拉不动了之后,最聪明的破局方式。
我有一个判断:AI视频工具正在经历和云计算一样的演进路径——从「卖原始算力」走向「卖完整服务」。 Seedance、Kling、Veo这些模型像是云计算早期的IaaS,给你一台虚拟机,剩下全靠你;OiiOii这种是PaaS甚至SaaS,整套生产线开箱即用。这条路走通的话,OiiOii不会是一个AI视频工具,它会是第一个AI视频公司。
说实话,OiiOii不是万能的。如果你要做真人短剧、需要精确的舞蹈动作控制,或者做系列番剧需要跨集保持角色一致,目前可能还不是它最擅长的场景。
但如果你想做单集动画、MV、品牌宣传片、故事短片,特别是你有好故事但不想花大量时间手搓提示词,OiiOii的分镜能力确实能帮你省掉很多工作,同时让成片质量上一个台阶。
150+种风格可以选,从日漫到3D皮克斯风到真人风格都有。接入了满血版Seedance 2.0之后,画面质量也确实比之前好了不少。
作为一个看了2000多部电影的人,我一直觉得AI视频工具缺的不是画面质量,而是对创作流程的尊重。电影工业花了一百年建立起来的分工体系,从编剧到分镜师到摄影到剪辑,每个环节都有专业的人在做专业的事。
OiiOii可能是第一个认真把这套逻辑搬到AI视频里的产品。它给你的不是一个万能工具,是一个团队。你的位置是导演。
这个方向我觉得是对的。从今往后,做视频拼的不是谁手里的模型更强,是谁雇得起更专业的AI员工。
最后说点私人的。我大学时一直有个隐隐的电影梦,看完《安妮霍尔》之后还认真买过一本《认识电影》。

17年过去了,我读这本书的状态一直是从入门到放弃,我可能还是拍不出那种东西。但我现在至少可以在周末花半小时,让OiiOii的7个AI员工帮我做出一段能帮助我表达想法的东西。
这件事本身,我觉得挺浪漫的。
传送门:www.oiioii.tv
目前注册不需要邀请码了,注册就送积分,每天登录也能领。感兴趣的可以自己试试,实际体验一下分镜功能,会比看文章更直观。




















热门跟贴