


今日凌晨,DeepSeek 在 GitHub 上发布了一项代号为“Engram”的最新研究成果,并同步上传了题为Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models(基于可扩展查找的条件记忆:大语言模型稀疏性的新维度)的学术论文。

这篇由梁文锋、DeepSeek 研究团队与北京大学联合署名的论文,一经发表就引发了广泛讨论。
此次研究带来了一项突破:在业界广泛采用的“混合专家模型”(MoE)之外,DeepSeek 开辟了第二条提升模型效率的路径——“条件记忆”(Conditional Memory)。如果说 MoE 解决了“如何高效计算”的问题,那么新提出的 Engram 架构则试图解决“如何高效存储与提取知识”的难题。
在此前的 DeepSeek-V2 和 V3 取得巨大成功后,基于 Transformer 的 MoE 架构已成为最具代表性、应用最广泛的稀疏化方案之一。MoE 通过“条件计算”(Conditional Computation)机制,即在处理每个词元(Token)时仅激活模型参数的一小部分,成功打破了模型规模与推理成本之间的线性约束。
然而,DeepSeek 研究团队指出,尽管 MoE 极大地优化了计算效率,在当前以注意力与前馈网络为核心的 Transformer 范式下,模型并不具备显式、可寻址的知识查找机制。
在现有的架构中,模型记忆知识的方式是隐式的。当模型需要回答“法国的首都是哪里”时,它无法像人类查阅字典那样直接检索出“巴黎”这个词,而是需要通过多层注意力机制(Attention)和前馈神经网络(FFN)进行复杂的矩阵运算,实际上是在通过计算来模拟检索过程。
这种机制造成了巨大的资源浪费:模型不得不动用宝贵的推理算力去“死记硬背”大量固定的事实性知识(如人名、地名、固定搭配等),这不仅效率低下,还挤占了模型处理复杂逻辑推理的“脑容量”。

针对这一点,DeepSeek 提出了“条件记忆”的概念,并设计了实体模块 Engram 来加以实现。Engram 的设计灵感源自自然语言处理(NLP)领域经典的 N-gram(N 元语法)模型,但在深度学习语境下进行了现代化改造。传统的 N-gram 依靠统计词汇共现频率来预测下一个词,而 Engram 则将其转化为一种可学习的、基于哈希(Hash)的向量检索系统。

具体而言,Engram 模块被嵌入到 Transformer 的主干网络中,与 MoE 层并行或交替工作。当模型处理输入文本时,Engram 不依赖深层神经网络计算,而是通过两步轻量化的检索与融合操作完成信息注入:
首先是“检索”,它将当前的局部上下文(例如最近出现的几个词)进行压缩并通过多头哈希映射,在算法层面实现近似 O(1) 的常数时间查表,并通过预取机制在系统层面将实际延迟控制在极低水平;其次是“融合”,通过一个上下文感知的门控机制(Gating Mechanism),将检索到的静态记忆向量与模型计算出的动态隐藏状态进行加权融合。
我们可以将传统的 Transformer 模型想象一个不仅需要理解题意,还需要现场推导所有数学公式和历史数据的考生;而搭载了 Engram 的模型,则相当于被允许带入考场一本百科全书。遇到固定的知识点,Engram 直接查表获得答案,而将宝贵的“大脑”算力集中用于处理从未见过的复杂逻辑题。这种“计算”与“记忆”的解耦,正是 DeepSeek 新架构的核心逻辑。
这项研究并不仅停留在理论层面,DeepSeek 在论文中披露了名为“稀疏性分配”(Sparsity Allocation)的关键发现,揭示了模型性能背后的数学规律。研究人员在严格控制总参数量和计算量(FLOPs)不变的前提下,系统性地调整了分配给 MoE 专家与 Engram 记忆表的参数比例。
实验结果呈现出一条清晰的“U 型曲线”:最佳的模型性能既不出现在纯粹的 MoE 架构中,也不出现在过度依赖记忆的架构中,而是当大约 20% 至 25% 的稀疏参数预算分配给 Engram,而剩余部分留给 MoE 时(即ρ≈75% -80% 时),模型性能达到最佳。
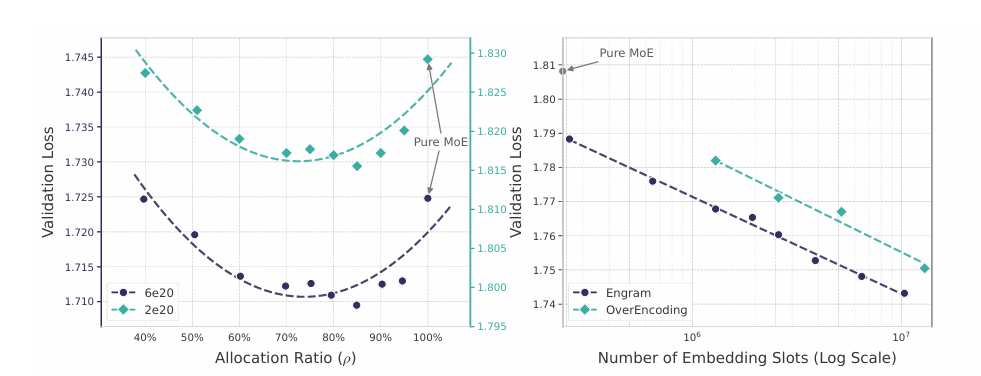
基于这一发现,DeepSeek 训练了一个拥有 270 亿参数的 Engram-27B 模型,并在同等参数规模和计算消耗下,与标准的 MoE-27B 模型进行了全方位的对比测试。结果显示,引入条件记忆机制后,模型在多个关键维度上实现了性能的显著跃升。
在知识密集型任务中,Engram 的优势符合预期。例如在衡量综合知识水平的 MMLU(大规模多任务语言理解)基准测试中,Engram-27B 的得分比基准模型高出 3.4 分;在中文综合基准 CMMLU 上,提升幅度更是达到了 4.0 分。这直接证明了外挂式的高效记忆模块能显著扩充模型的知识库。
不过,更令人意外的是 Engram 在通用推理能力上的表现。在衡量复杂推理能力的 BBH(Big-Bench Hard)基准上,Engram 模型取得了 5.0 分的巨大提升;在 ARC-Challenge 科学推理任务中提升了 3.7 分。甚至在传统认为高度依赖逻辑推演的代码生成(HumanEval +3.0)和数学解题(MATH +2.4)任务中,Engram 同样表现出了显著优势。

为何一个看似负责“死记硬背”的记忆模块,能提升模型的逻辑推理能力?DeepSeek 团队利用 LogitLens 和 CKA(中心核对齐)等可解释性工具进行了深入的机理分析,得出了一个极具洞察力的结论:Engram 有效增加了模型的“有效深度”(Effective Depth)。
分析显示,在没有 Engram 的传统模型中,底层的许多神经网络层实际上在忙于构建基础的词法组合和短语模式,这是一种低级的“特征重构”工作。而在引入 Engram 后,这些局部的、固定的语言模式(如“纽约”后紧接“时代广场”,“人工智能”是一个专有名词),这些都直接通过查表解决。
这使得模型的主干网络从繁琐的浅层任务中解脱出来,能够将更多的层数和注意力资源投入到更高层级的语义理解和逻辑推演中。换言之,Engram 通过承担记忆职能,在不增加层数的前提下,提高了模型用于复杂推理的“有效深度”。

此外,Engram 架构还在长文本处理(Long Context)领域展现出了意想不到的结构性优势。在处理长篇文档时,注意力机制往往面临巨大的计算压力。DeepSeek 的研究表明,文本中大量的依赖关系其实是局部的(Local),可以通过 N-gram 查找来解决。Engram 负责处理这些局部依赖,从而释放了 Transformer 全局注意力机制的容量,使其能更专注于捕捉跨度极大的长程关联。
在极具挑战性的“大海捞针”(Needle In A Haystack)测试中,Engram-27B 在该测试中的表现显著优于基准模型。。在多查询(Multi-Query)设置下,其准确率从基准 MoE 模型的 84.2% 飙升至 97.0%;在变量跟踪(Variable Tracking)任务中,准确率从 77.0% 提升至 89.0%。这意味着,搭载 Engram 的模型在处理法律合同分析、长篇小说理解或大型代码库维护等需要极高精度的长文本任务时,将具备更强的鲁棒性。

除了模型性能层面的突破,DeepSeek 延续了其一贯的“高效基础设施”理念,在 Engram 的工程实现上做到了极致。在当前的硬件环境下,显存(HBM)往往是制约大模型规模的瓶颈。然而,Engram 展现出了基础设施感知(Infrastructure-aware)的特性。
与 MoE 依赖运行时动态路由不同,Engram 的检索是基于输入文本的确定性哈希。这意味着,系统在正式计算某一层之前,就已经确切知道需要用到哪些记忆向量。这种确定性使得“预取”(Prefetching)策略成为可能。
DeepSeek 在实验中成功演示了将一个高达 1,000 亿参数的 Engram 嵌入表完全存储在廉价的主机内存(CPU DRAM)中,而非昂贵的 GPU 显存里。在模型计算前序层级时,系统通过 PCIe 通道异步地将所需的记忆数据搬运至 GPU。
实验数据显示,即使在 1,000 亿参数的超大规模下,这种跨硬件的存储与计算解耦方案带来的额外推理延迟也不到 3%。这一工程结果表明,在特定的系统设计与实验条件下,模型参数规模不再严格受限于 GPU 显存容量。理论上,这一设计为未来 DeepSeek 挂载 TB 级别的超大规模记忆库提供了可行路径,而无需成倍增加昂贵的算力集群成本。
综合此次发布的 Engram 论文,以及今年元旦期间 DeepSeek 发布的关于“流形约束超连接”(Manifold-Constrained Hyper-Connections, mHC)的研究,DeepSeek-V4 的架构开始逐渐具象化。
如果说 MoE 架构(条件计算)是 DeepSeek-V2/V3 的基石,那么 V4 有望在架构层面呈现出更高程度的整合性:它将融合 mHC 以优化专家间的通信效率,同时引入 Engram 作为独立的“海马体”模块。这种架构不再是简单的参数堆叠,而是向着人类大脑“计算与记忆分离、协同工作”的生物学原理迈进。MoE 负责动态的逻辑处理,Engram 负责静态的知识检索,两者互为补充,共同构成了一个更高效、更博学且更擅长推理的智能系统。

Github 论文地址:https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf
运营/排版:何晨龙


























热门跟贴