



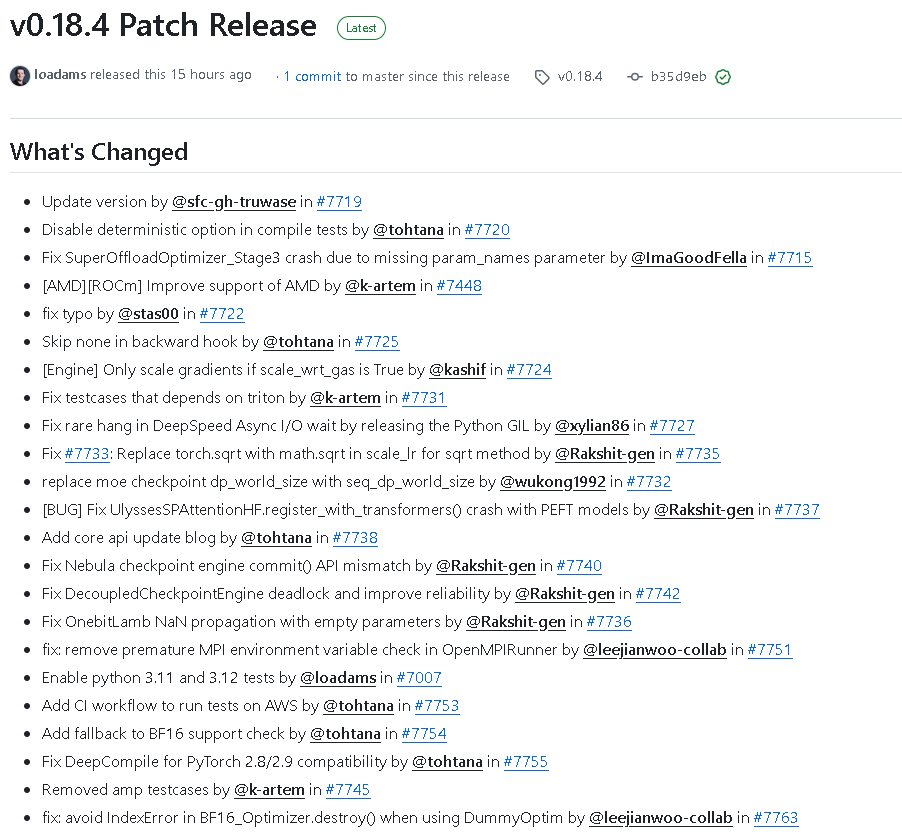

2026 年 1 月 8 日,DeepSpeed 官方正式发布 v0.18.4 版本。本次更新主要聚焦于 性能优化、稳定性修复、兼容性增强,并带来了对 Python 3.11 / 3.12、PyTorch 2.8 / 2.9 与 AMD ROCm 的全面支持。该版本共包含 23 次提交,涉及 14 位贡献者,修改文件数 41 个,是一次重要的维护与优化版本。下面我们详细解读 v0.18.4 的更新内容。
一、核心更新与改进 ✅ 1. 版本管理与测试体系优化
• 更新版本号并同步测试框架。
• 在编译测试中禁用 deterministic 选项,以提升测试灵活性与速度。
• 在持续集成(CI)层面新增 AWS 测试工作流,使测试环境更加多样化和稳定。
• 启用对 Python 3.11 与 3.12 的自动化测试支持,进一步拓宽兼容边界。
• 修复 SuperOffloadOptimizer_Stage3 崩溃问题(由缺失
param_names参数引起)。• 改进 Engine 模块,仅在
scale_wrt_gas为 True 时才对梯度进行缩放,从而提升计算效率。• 修复 Nebula Checkpoint Engine 的
commit()API 不匹配问题,完善接口一致性。• 修复 DecoupledCheckpointEngine 潜在死锁问题,并增强整体可靠性。
• 优化 DeepSpeed Async I/O 机制,通过释放 Python GIL 解决罕见的异步等待卡死问题。
• 修复 OnebitLamb 在空参数情况下出现的 NaN 传播问题,提升分布式优化器稳定性。
• 修复 BF16_Optimizer 在 DummyOptim 模式下的 IndexError 异常,保障兼容性。
• 改进 DeepCompile 模块,以确保与 PyTorch 2.8 / 2.9 的高度兼容。
• 替换
torch.sqrt为math.sqrt,解决因不同实现导致的学习率缩放误差问题。• 更正 MOE 检查点中的分布式尺寸定义,将
dp_world_size替换为seq_dp_world_size。• 修复 UlyssesSPAttentionHF 与 PEFT 模型在注册时的兼容性错误。
• 针对部分依赖 Triton 的测试用例进行修复,确保多平台一致性。
本次版本显著提升了 AMD GPU(ROCm 平台)的支持能力,对相关后端进行了进一步优化。部分 AMP 测试用例被跳过,以确保在 AMD 环境下的执行稳定性。
✅ 2. BF16 支持检查优化
新增 BF16 支持的 fallback 检测逻辑,可在硬件不支持时自动回退至安全路径,提升兼容性与健壮性。
三、代码质量与小幅修正
• 修复若干拼写错误,提升代码可读性。
• 在反向传播 Hook 中跳过 None 值,修复潜在异常。
• 移除 OpenMPIRunner 中过早的 MPI 环境变量检测逻辑,增强启动灵活性。
• 移除了旧版 AMP 相关测试用例,保持代码库简洁。
• 补充并发布 Core API 更新日志,完善官方文档体系。
代码地址:github.com/deepspeedai/DeepSpeed
DeepSpeed v0.18.4 是一次高质量的维护性更新,覆盖了 兼容性、稳定性、测试体系、性能优化 等多个方面,对 AMD 生态及高版本 Python / PyTorch 的支持尤为显著。对于研发者而言,本次版本在大规模分布式训练的可靠性上带来了切实提升。
版本要点回顾:
• ✅ 全面支持 Python 3.11 / 3.12 与 PyTorch 2.8 / 2.9
• ✅ 增强 AMD ROCm 兼容与性能
• ✅ 提升 DeepSpeed Async I/O、Checkpoint 引擎稳定性
• ✅ 优化梯度缩放与学习率计算逻辑
• ✅ 改进 BF16、MOE、Ulysses 等子模块
• ✅ 新增 AWS 测试工作流,强化 CI 能力
结语:
随着 v0.18.4 的发布,DeepSpeed 在多平台深度训练生态中进一步巩固领先地位,为开发者提供了更高效、更可靠的训练引擎支持。未来版本将继续深化异构计算与自定义算子的优化,让大规模模型训练更快、更稳。




























热门跟贴