



近日,由香港科技大学 MMLab 及合作团队完成的研究工作「UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors」被计算机图形学顶级会议 SIGGRAPH 2026 正式接收。

- 论文地址:https://arxiv.org/pdf/2605.00658
- 代码:https://github.com/houyuanchen111/UniVidX
- 项目主页:https://huggingface.co/houyuanchen/UniVidX

图 1:该图系统性展示了 UniVidX 在多模态视频生成中的统一建模能力,覆盖 Text→X、X→X 及 Text&X→X 三类核心范式。上半部分为 UniVid-Intrinsic,支持逆向渲染、重打光、Intrinsic 生成等任务;下半部分为 UniVid-Alpha,支持 RGBA 生成、视频抠图与视频 inpainting 等任务。结果表明,单一框架即可覆盖原本需要多个独立模型完成的复杂视频图形任务。
该工作提出了一个面向多模态视频生成与理解的一体化统一框架 UniVidX,在多项视频图形任务上达到或刷新当前最优性能,标志着视频扩散模型在通用化方向上的重要进展。

图 2:该图展示了 UniVidX 的核心结构,包括随机条件掩码、解耦门控 LoRA 以及跨模态自注意力。不同模态在训练中被动态划分为条件或目标,从而实现全方向生成能力。通过共享注意力机制与模块化参数适配,模型在保证一致性的同时有效避免模态间干扰。
长期以来,视频图形学与视频生成领域的发展呈现出明显的任务割裂。不同问题往往依赖独立建模,例如视频逆向渲染、视频重打光、视频抠图、视频 inpainting 以及文生视频等任务,通常需要分别训练专用模型来完成。
这种以固定输入——输出映射为核心的建模方式,限制了模型对复杂真实场景的适应能力,也阻碍了跨任务知识的共享与迁移。在实际应用中,视频内容往往涉及多种模态与多种操作的组合,传统方法难以提供统一且高效的解决路径。

图 3:该图对比了 UniVid-Intrinsic 与现有方法在 Intrinsic 生成任务中的表现。相比基线方法存在的模态错位与细节缺失,UniVidX 在 RGB、反照率与法线之间保持了更高的一致性。结果表明,该方法能够稳定生成具有物理一致性的多模态视频序列。
针对这一问题,UniVidX 从建模范式上进行了系统性重构。该框架的核心思想,是将不同视频图形任务统一为多模态条件生成问题,使任意模态既可以作为输入条件,也可以作为生成目标,从而实现「任意模态到任意模态」的统一建模能力。在这一统一空间中,RGB 视频、法线、反照率、光照、Alpha 通道以及前景背景等信息不再彼此割裂,而是通过共享的生成机制进行协同建模。

图 4:该图展示了 UniVidX 在 Intrinsic 生成和 RGBA 生成任务中的定量评测。无论在用户评分还是时间一致性指标上,UniVidX 均优于现有方法。值得注意的是,该方法可实现多层分解生成,体现出更强的统一建模能力。
为了实现这一统一能力,UniVidX 在模型结构与训练机制上提出了一系列关键设计。
首先,通过随机条件掩码机制,模型在训练过程中不断改变输入与输出模态的划分,从而学习全方向的生成关系,而非固定映射。这一机制使模型具备更强的泛化能力,可以适应多样化的任务需求。
其次,通过解耦门控 LoRA,模型为不同模态分配独立参数空间,并在对应模态作为生成目标时动态激活,从而有效避免不同模态之间的参数干扰,同时保留预训练扩散模型的原始生成能力。
此外,跨模态自注意力机制通过在不同模态之间共享信息,实现了几何、光照与语义层面的统一约束,显著提升了生成结果的一致性与稳定性。

图 5:该表系统比较了 UniVid-Intrinsic 与多种代表性方法在反照率、光照、法线及正向渲染任务上的性能。UniVidX 在 PSNR、SSIM 及 LPIPS 等指标上整体领先。结果验证了统一框架在多任务场景中的综合优势。
在具体实现上,研究团队基于该框架构建了两个代表性模型,用于覆盖不同类型的视频图形任务。UniVid-Intrinsic 面向 Intrinsic,可统一处理 RGB、反照率、辐照度和法线等模态,支持文本到 Intrinsic 生成、视频逆向渲染、正向渲染以及视频重打光等任务。
与此同时,UniVid-Alpha 面向视频层级分解与合成,统一建模混合视频、前景、背景与 Alpha 通道,支持视频抠图、视频 inpainting 以及前景与背景替换等关键应用。两个模型在统一框架下共同支持 Text→X、X→X 以及 Text&X→X 三类生成范式,总计覆盖十五类典型视频任务,验证了该方法的广泛适用性。

图 6:该图展示了不同方法在逆向渲染和正向渲染任务中的视觉效果。相比其他方法存在的伪影与细节丢失,UniVidX 生成结果更接近真实分布。尤其在光照一致性与几何细节方面,表现出更高的稳定性与精度。
值得关注的是,UniVidX 在数据效率方面表现出显著优势。实验结果表明,即使在不足千条视频的数据规模下,模型仍能够在多个任务上达到或超过现有最优方法,并在真实场景与分布外数据上保持良好的泛化能力。这一现象表明,该方法并非依赖大规模任务数据进行学习,而是通过合理的结构设计与训练策略,有效激活并利用了预训练视频扩散模型中蕴含的动态世界先验。

图 7:该表展示了 UniVidX 在真实世界 MAW 数据集上的反照率估计性能。尽管仅在合成数据上训练,模型仍取得最佳强度误差指标,并在色度误差上保持竞争力。结果表明该方法具备良好的跨域泛化能力。
在系统评测方面,UniVidX 在多个关键任务中取得领先表现。在视频逆向渲染与正向渲染任务中,模型在 PSNR、SSIM 及感知指标上整体优于现有扩散模型方法;在法线估计任务中,在显著减少训练数据规模的情况下仍达到接近甚至优于专用模型的性能;在视频抠图任务中,作为无需额外辅助信息的模型,其结果超过多种依赖 mask 输入的方法。同时,在文本驱动生成任务中,模型在视觉质量、语义一致性以及跨模态一致性方面均获得更高评价,且在时间一致性方面显著优于图像级方法。

图 8:该表对比了 UniVidX 与多种专用法线估计方法的性能。尽管训练数据规模显著更小,UniVidX 仍达到接近甚至优于部分专用模型的精度。该结果体现了利用扩散先验进行统一建模的高数据效率优势。
从更高层面来看,UniVidX 的价值不仅体现在单项任务性能的提升上,更体现在其系统能力的整合与扩展。由于所有模态共享统一的生成框架,不同任务可以在同一模型内部灵活组合,从而支持更加复杂的视频编辑与内容生成流程。
例如,可以先进行视频逆向渲染获取物理属性,再基于文本进行重打光或材质编辑;也可以通过 Alpha 分解实现视频 inpainting 与背景替换。这种多模态可组合的能力,使 UniVidX 从单一模型扩展为面向复杂应用的统一视频图形引擎。
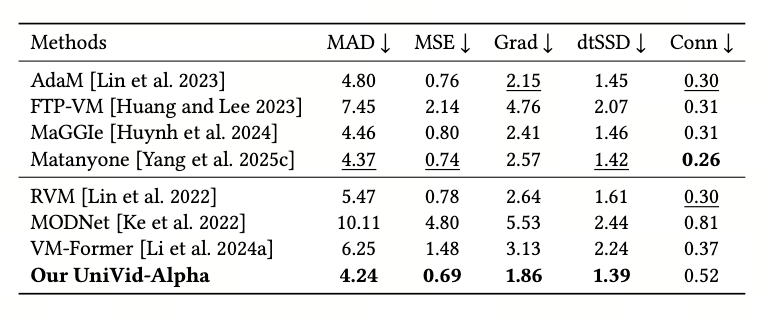
图 9:该表展示了 UniVid-Alpha 在视频抠图任务上的定量表现。作为无需辅助 mask 输入的方法,UniVidX 在 MAD、MSE 等关键指标上优于多种现有方法。结果说明扩散模型先验能够有效替代传统显式分割信号。
总体而言,UniVidX 的提出标志着视频扩散模型正在从单一任务工具向通用视频图形基础模型转变。该工作验证了一个重要方向:在具备强大预训练先验的前提下,通过合理的多模态建模机制,可以将传统图形学中的分解、估计、生成与编辑任务统一到同一框架中。这一进展不仅为视频生成与理解提供了新的技术路径,也为自动驾驶仿真、具身智能、影视制作等领域的实际应用奠定了重要基础。
作者介绍
本文第一作者为南京大学本科生陈厚源,即将入学香港科技大学 MMLab 开展研究。本文通讯作者为香港科技大学 MMLab 饶安逸老师。值得一提的是,斯坦福大学博士生 Lvmin Zhang 也是本文作者之一,他此前曾与饶安逸老师合作完成 ControlNet、IC-Light 等代表性工作,其中 ControlNet 曾获 ICCV Marr Prize。此外,清华大学赵昊老师也为该工作提供了重要指导,共同推动了项目的完成。
![kimi agent集群,不管最终效果如何,这个排面很舒服很震撼[微笑] #agent](http://bjnewsrec-cv.ws.126.net/little334bbc9852cj00tee9bu002wd200q60112g00q60112.jpg)





















热门跟贴